MITMPROXY 插件不完全食用指南
MITMPROXY 插件不完全食用指南
程序介绍
Mitmproxy是一个开源的交互式的代理软件,基本上可以约等于Fiddler和没有各种渗透辅助插件的Burpsuie。
安装方法
Linux中:
sudo pip3 install mitmproxy
Macos中(可是我没有mac):
brew install mitmproxy
Windows中:可以直接在官网(https://www.mitmproxy.org/) 下载安装包或者
sudo pip3 install mitmproxy
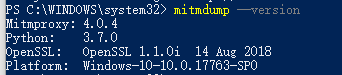
安装完成后可以在命令行中尝试输入 mitmdump --version 查看是否安装成功:
运行方法
命令行模式
mitmproxy -p 9999
默认在8080端口运行,-p可以指定输出端口。
windows下安装后默认是没有mitmproxy这个的,可以用mitmweb或者mitmdump。
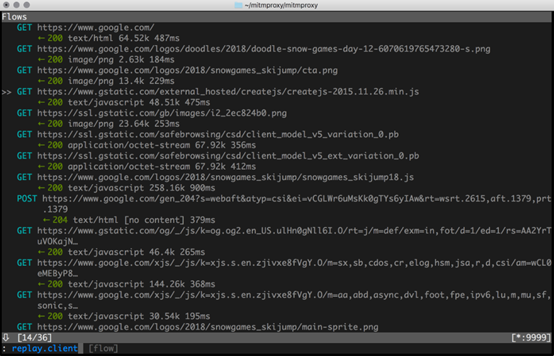
WEB模式
mitmweb -p 8081
简单模式
mitmdump -p 8080
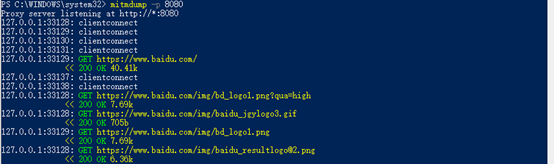
显示内容较简单,但是方便插件的调试 ,不过其实mitmweb打开后,命令行中依然可以打印出来脚本中输入的内容。
设置代理
2020年了还不会设置代理吗少年~~
安装证书
在设置好代理的情况下,直接访问 mitm.it,就可以点击对应的系统的证书就可以下载安装了,记得装到根证书中哦,可以避免后期一些麻烦:

证书使用中会出现一个错误”502Bad Gateway. unable to get local issuer certificate“,需要更新证书,找一个最新的cacert.pem替换certifi包(xx\python\Lib\site-packages\certifi)目录的证书,再次使用可以抓到包了
参考https://blog.csdn.net/hqzxsc2006/article/details/80981576
证书下载地址 https://curl.haxx.se/docs/caextract.html
证书安装成功,记得在启动时加上 --ssl-insecure 或者 -k 来无视证书错误哦~
mitmdump -p 8888 --ssl-insecure mitmdump -p 8888 -k
Powershell卡死问题
打开任意一个cmd或powershell窗口,然后在title栏右键,点击属性,在选项界面有个快速编辑模式,去掉即可
不过这样设置的话,就只能右键窗口-编辑-标记 来选取了。
Mitmweb打开时提示无法打开套接字
有时mitmweb打开时会提示 OSError: [WinError 10013] 以一种访问权限不允许的方式做了一个访问套接字的尝试,如下图所示:
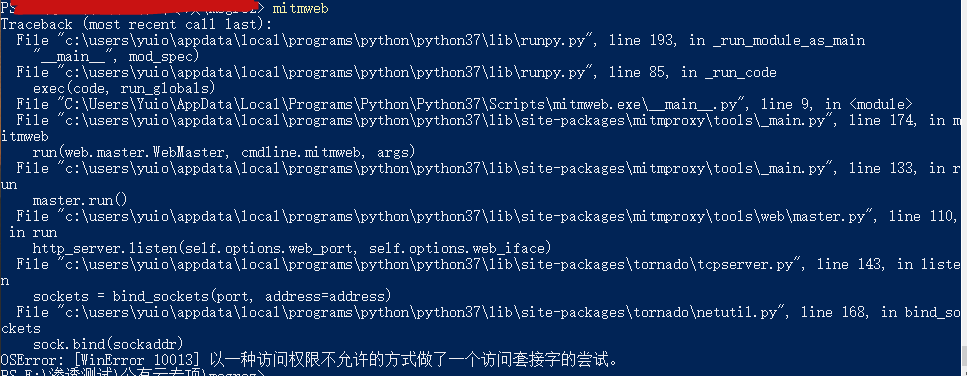
这样需要检查两个地方,一个是默认开放的代理端口8080,一个是开启web服务的端口8081,这两个端口不管哪一个被占用都是有这个错误提示的。
使用 --web-port 可以指定web服务的端口,使用 -p 可以指定代理的端口,
mitmweb --web-port 8999 -p 2545
如下图所示,就没啥问题了:

插件简单食用指南
插件需要python3环境的支持,使用前需要自行安装python3,并且
python3 -i pip3 install mitmproxy
用来安装mitmproxy模块。
简单示例
官方推荐的写法可以参考官方说明文档:https://docs.mitmproxy.org/stable/addons-overview/
插件结构:
from mitmproxy import ctx
class Counter: //自定义一个类,名字可以随意取
def request(self, flow): //生命周期函数
xxxxx
def xxx(): //自定义函数
xxx
addons = [
Counter() //输入之前自定义的类名
]
给展示一个简单的示例:
import mitmproxy.http
from mitmproxy import ctx
class Counter:
def request(self, flow: mitmproxy.http.HTTPFlow):
if "baidu.com" in flow.request.url:
ctx.log.info("你正在浏览百度")
addons = [
Counter()
]
在命令行中运行
mitmdump -s test.py
然后在挂了mitm代理的浏览器中访问百度,可以看到命令行中输出了对应的内容:
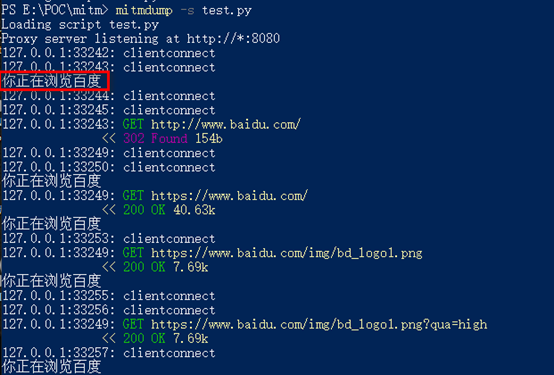
从官方的脚本示例库可以看到,通过插件可以实现修改请求头,修改请求内容,修改响应头,修改相应内容等功能:
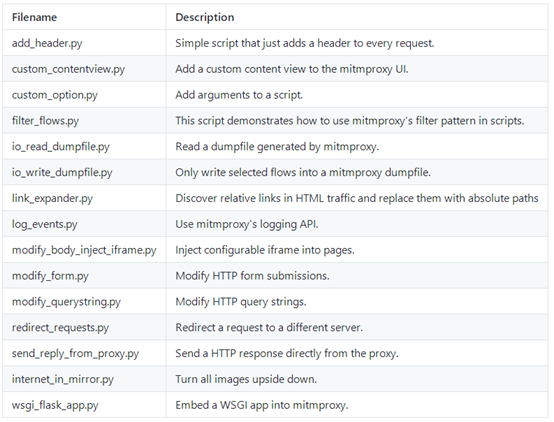
链接如下: https://github.com/mitmproxy/mitmproxy/tree/master/examples/simple
函数说明查看方式
其实看官方示例实现的方法都很简单,在查看文档时候,也会看到比较少的信息,所以需要自己查看对象的说明。依次执行以下命令即可:
python3 -m pydoc -w any python3 -m pydoc -p 5000
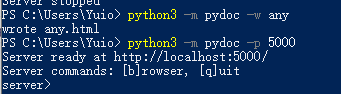
然后浏览器访问 localhost:5000 来查看当前python已安装模块的说明。
直接访问 http://127.0.0.1:5000/mitmproxy.http.html 就可以看到该模块中的函数:
HTTP Lifecycle
Mitmproxy支持的代理协议支持HTTP/HTTPS,TCP,WEBSOCKET的操作,不过本次就先来针对HTTP讲解吧,因为其他的我还没用过。可以参考官方对于生命周期的说明:https://docs.mitmproxy.org/stable/addons-events/
针对HTTP的操作,官方规定的1个生命周期有5种阶段:
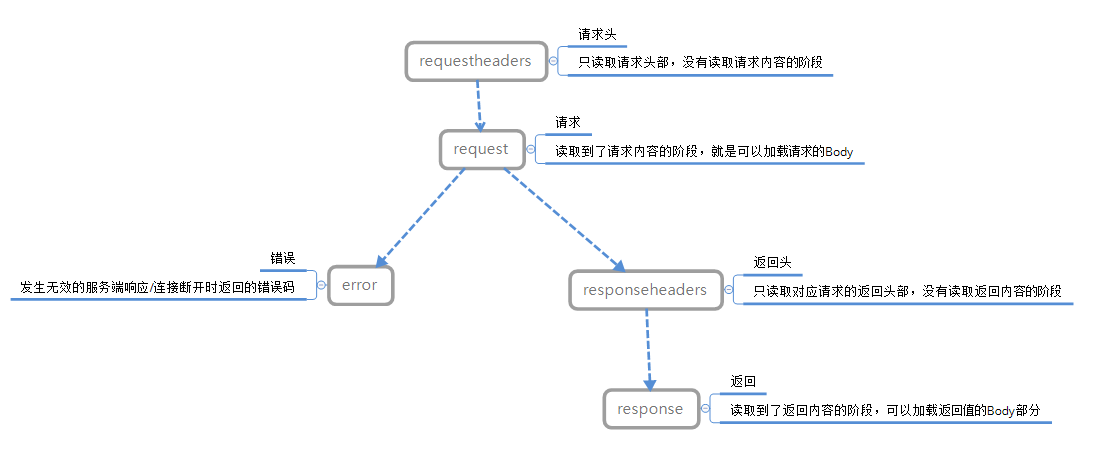
由于每个生命周期可以获取到的内容是不一样的,所以可能会有不同的参数值可以获取。
但是要记住的是:
- 一个生命周期对应的是一个HTTP请求流程,一个mitmproxy脚本的对应的也是一个生命周期也就是一个HTTP请求,不可以直接获取到上一个生命周期中的数据,例如先发了A请求,再发了B请求,不可以B请求中直接获取A请求的内容;
- 同一个生命周期中,如果一个阶段已经完成,下一个阶段可以直接使用上一个阶段的数据,例如在response中可以直接调用request中的body,而不需要额外操作。
一般情况下,我们使用request和response两个阶段的操作就可以完成很多事情了。
这个生命周期可以体现在自定义对象的函数中,其中有很多自带的如下所示:
from mitmproxy import ctx
class Counter: //自定义一个类,名字可以随意取
def request(self, flow): //请求
ctx.log.info("this is the request")
def response(self,flow):
ctx.log.info("this is the response")
........
addons = [
Counter() //输入之前自定义的类名
]
ctx.log.info()打印出来的就是信息,ctx.log.warn()打印出来就是警告,ctx.log.error()打印出来的就是错误。
这里也可以用printf()直接搞定,都可以打印出来的。
HTTP自带方法
Mitmproxy自带了很多了方法允许直接操作请求中的参数,比如修改请求头,请求方式,请求内容这些,都可以通过自带的方法直接修改,并且可以随便import python自带的库,比如hmac,hashlib, json,非常方便。
做个小例子来抓一下请求看看自带的方法都会打印出啥东西来吧:
示例的HTTP请求和返回值如下:
request:
POST / HTTP/1.1
Host: 192.168.1.60
Content-Length: 73
Accept: application/json, text/javascript, */*; q=0.01
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36
Content-Type: application/json; charset=UTF-8
Origin: http://192.168.1.60
Referer: http://192.168.1.60/
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Connection: close
{"method":"do","login":{"username":"admin","password":"0KcgeXhc9TefbwK"}}
response:
HTTP/1.1 200 OK
Connection: close
Content-Type: application/json
Cache-Control: no-cache
Expires: 0
Content-Length: 79
{ "error_code": -40401, "data": { "code": -40401, "time": 9, "max_time": 10 } }
脚本如下:
import mitmproxy
class Test:
def request(self, flow):
if flow.request.url=="http://192.168.1.60/": #这里的请求可以随意替换
#flow.request.headers
print("----flow.request.headers----完整的请求头,包含一般请求头的所有信息----")
print(type(flow.request.headers))
print(flow.request.headers)
#flow.request.url
print("----flow.request.url----请求的url,如 www.xxx.com/xx.php----")
print(type(flow.request.url))
print(flow.request.url)
#flow.request.host
print("----flow.request.host----请求的host,如 www.xxx.com----")
print(type(flow.request.host))
print(flow.request.host)
#flow.request.method
print("----flow.request.method----请求的方式,如POST,GET,OPTIONS等----")
print(type(flow.request.method))
print(flow.request.method)
#flow.request.cookies
print("----flow.request.cookies----请求的cookies----")
print(type(flow.request.cookies))
print(flow.request.cookies)
#flow.request.scheme
print("----flow.request.scheme----请求是http还是https----")
print(type(flow.request.scheme))
print(flow.request.scheme)
#flow.request.path
print("----flow.request.path----请求的路径,如/xx.php----")
print(type(flow.request.path))
print(flow.request.path)
#flow.request.get_text()
print("----flow.request.get_text()----获取str类型的Body----")
print(type(flow.request.get_text()))
print(flow.request.get_text())
def response(self,flow):
if flow.request.url=="http://192.168.1.60/": # 也可以直接用request中的数据哦~支持的方法和request基本相同
#flow.response.status_code
print("----flow.response.status_code----返回的代码,如200,404等----")
print(type(flow.response.status_code))
print(flow.response.status_code)
#flow.response.reason
print("----flow.response.reason----返回的理由,如200就是OK,404就是NOT FOUND----")
print(type(flow.response.reason))
print(flow.response.reason)
#flow.response.get_text()
print("----flow.response.get_text()----获取str类型的Body----")
print(type(flow.response.get_text()))
print(flow.response.get_text())
addons = [
Test()
]
使用以下命令打开代理,并且加载插件,记得将浏览器代理设置为8888端口
mitmdump -s test.py -p 8888
打印出来的信息如下图所示:
----flow.request.headers----完整的请求头,包含一般请求头的所有信息----
class 'mitmproxy.net.http.headers.Headers'>
Headers[(b'Host', b'192.168.1.60'), (b'Proxy-Connection', b'keep-alive'), (b'Content-Length', b'73'), (b'Accept', b'application/json, text/javascript, */*; q=0.01'), (b'X-Requested-With', b'XMLHttpRequest'), (b'User-Agent', b'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'), (b'Content-Type', b'application/json; charset=UTF-8'), (b'Origin', b'http://192.168.1.60'), (b'Referer', b'http://192.168.1.60/'), (b'Accept-Encoding', b'gzip, deflate'), (b'Accept-Language', b'zh-CN,zh;q=0.9')]
----flow.request.url----请求的url,如 www.xxx.com/xx.php----
class 'str'>
http://192.168.1.60/
----flow.request.host----请求的host,如 www.xxx.com----
class 'str'>
192.168.1.60
----flow.request.method----请求的方式,如POST,GET,OPTIONS等----
class 'str'>
192.168.1.60
----flow.request.cookies----请求的cookies----
class 'mitmproxy.coretypes.multidict.MultiDictView'>
MultiDictView[]
----flow.request.scheme----请求是http还是https----
class 'str'>
http
----flow.request.path----请求的路径,如/xx.php----
class 'str'>
/
----flow.request.get_text()----获取str类型的Body----
class 'str'>
{"method":"do","login":{"username":"admin","password":"0Kcgebhc9TefbwK"}}
----flow.response.status_code----返回的代码,如200,404等----
class 'int'>
200
----flow.response.reason----返回的理由,如200就是OK,404就是NOT FOUND----
class 'str'>
OK
----flow.response.get_text()----获取str类型的Body----
class 'str'>
{ "error_code": -40401, "data": { "code": -40401, "time": 9, "max_time": 10 } }
可以看到通过自带的方式已经获取大部分值以及其数据类型了,那么怎么修改其中的值呢。
如果要修改请求中的header中Referer的内容,可以直接赋值:
flow.request.headers["Referer"]="http://192.168.1.61/"
如果要修改url, 依然可以直接赋值:
flow.request.url=="http://192.168.1.61/"
不过请求内容会特殊一些,需要使用单独的flow.request.set_text()方法:
flow.request.set_text("LPBENLF")
这样就把请求的内容从原来的内容变成了”LPBENLF“
官方说明中可以直接用flow.request.urlencoded_form打印出字典格式的内容,可以自己试下。我个人还是习惯用json处理了再扔回去。
真!示例-实现请求自签名
实际渗透测试的过程中,经常会遇到请求有完整性和防重放检查的情况,比如请求的内容和发送时间放在一起做了MD5或者其他的检查,导致自己修改或者自动化测试时发送的请求因为校验不对而无法继续进行下去。
这时候使用MITMPROXY的插件,通过自动计算需要校验的内容和结果就可以简简单单的绕过这种签名了。
假设某网站请求格式如下:
POST https://target.com/user/list HTTP/1.1
Host: target.com
Connection: keep-alive
Content-Length: 12
Origin: https://target.com
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36
Content-MD5: tAKTsTuwZGPfDpTB2cS7dw==
Content-Type: application/json;charset=UTF-8
Accept: application/json, text/plain, */*
TARGET-TIME: 11:01:13
TARGET-SIGN:xxxxxxx
Referer: https://target.com/
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
{"limit":20}
假设已经通过js或者其他方法找到了他的算法,TARGET-SIGN的值是通过 TARGET-TIME作为密钥,URL+Content-MD5作为密文的SHA1算法 来计算出来的,通过mitmproxy可以非常简单的完成证书的签名机制:
import hashlib
import time
import hmac
import base64
from mitmproxy import ctx
#根据请求内容替换请求中的sign
class Modify:
def request(self, flow):
#判断是不是要签名的请求
if 'target.com' in flow.request.url and "TARGET-SIGN" in flow.request.headers:
#生成时间 格式11:01:13
ctime = time.strftime("%H:%M:%S", time.localtime())
# 新计算的TIME直接放入请求头
flow.request.headers["TARGET-TIME"]=ctime
# 生成content-md5
values=flow.request.get_text()
md5 = hashlib.md5()
md5.update(values.encode('utf-8'))
hmd5 = md5.digest()
base_md5 = base64.b64encode(hmd5)
# 新计算的MD5直接放入请求头
flow.request.headers["Content-MD5"]=base_md5
#提取URL
url_c=flow.request.url
url_c1=url_c.split(".com",1)
url=url_c1[1]
#计算签名并且拼接请求
unsign=url + base_md5.decode()
print("未签名的请求头如下\n"+unsign+"\n---------------------\n")
#hmac-sha1(密钥,密文),python就是这么用
hsign=hmac.new(ctime.encode('utf-8'),unsign.encode('utf-8'),digestmod='sha1')
base_sign=base64.b64encode(hsign.digest())
#签名赋值到请求中
flow.request.headers["TARGET-SIGN"] = base_sign.decode()
print(flow.request.headers)
print("********************** "+flow.request.url+"修改成功")
addons = [
Modify()
]
总结
因为有python库的支持,mitmproxy脚本能实现的功能真的很多,网上看到大佬们写的头脑王者自动发答案,突破反爬机制实现的功能,基本只要能想到就能做到。文中只是简单的介绍了可以常用的方法和使用范例,更多的用法需要各位自己去挖掘了。
参考文章:
https://www.cnblogs.com/zhangmingyan/p/11358886.html
https://docs.mitmproxy.org/stable/