从零开始的 kernel pwn 入门 - I:Linux kernel 简易食用指南
从零开始的 kernel pwn 入门 - I:Linux kernel 简易食用指南

0x00.一切开始之前
前言
当前阶段在 CTF 比赛中 pwn 类型的题目主要以 Linux 下的漏洞利用为基础,而Linux 下的漏洞利用又可以分为用户态与内核态两个方面的漏洞利用——我们在各种比赛中最常接触到的是前者,很少有接触到后者的机会(笔者最近打的几场比赛中只有 TCTF/0CTF FINAL 出了两道)
但若是我们将目光放得更长远些,对操作系统内核的利用的研究,毫无疑问是安全界十分热门的一个方向,因此本系列文章并非 CTF 导向的教程,笔者更愿意向大家介绍现实中的 Linux kernel exploit,即真实世界中的pwn
不过不可否认的是,CTF 仍然是一个十分适合入门的方法,因此本系列教程当中仍然会以讲解近些年 CTF 中的 kernel pwn 题目为主,kernel cve 为辅,来帮助大家更好地踏入kernel pwn 的世界
文章计划
笔者粗略计划,在接下来的一系列文章当中,你将接触到以下的内核攻击手法:
- 内核栈利用
- 返回导向编程(ROP)
- ret2usr
- SMEP-BYPASS
- ret2dir
- ret2usr
- KPTI bypass
- 返回导向编程(ROP)
- 内核“堆”利用
- Use After Free
- 堆溢出
- Off-by-one
- 条件竞争
- double fetch
- userfaultfd
- 堆喷(heap spraying)
- qemu逃逸
- ……
同时你还将接触到一些 kernel cve 的简单解析,以及使用 syzkaller、AFL-fuzz 等自动化的漏洞挖掘工具的基本用法
目标人群:
重要的事情说三遍:
该系列文章不适用于刚刚入门pwn的萌新!该系列文章不适用于刚刚入门pwn的萌新!该系列文章不适用于刚刚入门pwn的萌新!
笔者个人建议,在入门 kernel pwn 之前,你应当对用户态下的基本利用手法了如指掌,且至少完成对操作系统这一门课程系统性的学习
本篇内容
作为本系列的第一篇文章,在正式进入到 kernel pwn 的世界之前,笔者还是想先向大家介绍一些操作系统的基础知识,包括:
- 操作系统基础
- 内核保护机制
- 内核编译、运行、替换
- 内核调试基本方法(qemu + gdb)
- 基本 LKM 的编写入门
- CTF 中 kernel 类题目的部署方式
0x01.操作系统基本知识补充
在入门之前,我们首先得需要了解,操作系统是什么?她和我们普通的应用程序有何不同?
本篇文章中笔者将带着大家简单地操作系统这一门课程过一遍,主要讲解 Linux kernel
一、内核
操作系统(Operation System)本质上也是一种软件,可以看作是普通应用程式与硬件之间的一层中间层,其主要作用便是调度系统资源、控制IO设备、操作网络与文件系统等,并为上层应用提供便捷、抽象的应用接口
而运行在内核态的内核(kernel)则是一个操作系统最为核心的部分,提供着一个操作系统最为基础的功能
这张十分经典的图片说明了Kernel在计算机体系结构中的位置:

kernel的主要功能可以归为以下三点:
- 控制并与硬件进行交互
- 提供应用程式运行环境
- 调度系统资源
包括 I/O,权限控制,系统调用,进程管理,内存管理等多项功能都可以归结到以上三点中
与一般的应用程式不同,kernel的crash通常会引起重启
通常来说我们可以把内核架构分为两种:宏内核和微内核,大致架构如下图所示:

宏内核(英语:Monolithic kernel),也译为集成式内核、单体式内核,一种操作系统内核架构,此架构的特性是整个内核程序是一个单一二进制可执行文件,在内核态以监管者模式(Supervisor Mode)来运行。相对于其他类型的操作系统架构,如微内核架构或混合内核架构等,这些内核会定义出一个高端的虚拟接口,由该接口来涵盖描述整个电脑硬件,这些描述会集合成一组硬件描述用词,有时还会附加一些系统调用,如此可以用一个或多个模块来实现各种操作系统服务,如进程管理、并发(Concurrency)控制、存储器管理等。
通俗地说,宏内核几乎将一切都集成到了内核当中,并向上层应用程式提供抽象API(通常是以系统调用的形式)
Unix与类Unix便是宏内核
对于微内核而言,大部分的系统服务(如文件管理等)都被剥离于内核之外,内核仅仅提供最为基本的一些功能:底层的寻址空间管理、线程管理、进程间通信等
Windows NT与Mach都宣称采用了微内核架构,不过本质上他们更贴近于混合内核(Hybrid Kernel)——在内核中集成了部分需要具备特权的服务组件

本文中我们主要讨论Linux内核
二、分级保护域
分级保护域(hierarchical protection domains)又被称作保护环,简称 Rings ,是一种将计算机不同的资源划分至不同权限的模型
在一些硬件或者微代码级别上提供不同特权态模式的 CPU 架构上,保护环通常都是硬件强制的。Rings是从最高特权级(通常被叫作0级)到最低特权级(通常对应最大的数字)排列的
在大多数操作系统中,Ring0 拥有最高特权,并且可以和最多的硬件直接交互(比如CPU,内存)
内层ring可以任意调用外层ring的资源
Intel的CPU将权限分为四个等级:Ring0、Ring1、Ring2、Ring3,权限等级依次降低
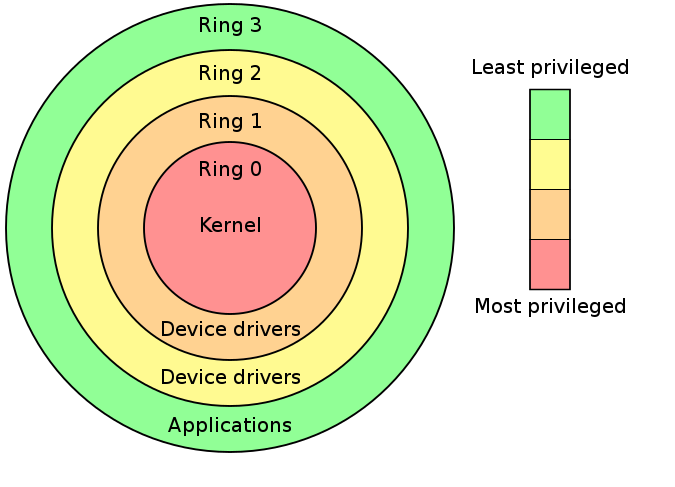
大部分现代操作系统只用到了ring0 和 ring3,其中 kernel 运行在 ring0,用户态程序运行在 ring3
使用 Ring Model 是为了提升系统安全性,例如某个间谍软件作为一个在 Ring 3 运行的用户程序,在不通知用户的时候打开摄像头会被阻止,因为访问硬件需要使用 being 驱动程序保留的 Ring 1 的方法
操作系统本身便是一个运行在内核态的程序,当计算机通电之后处于实模式下,从磁盘上载入第一个扇区(MBR)执行,之后载入第二引导程序(Linux通常用 GNU Grub),由第二引导程序来将操作内核载入到内存当中并跳转到内核入口点,将控制权移交内核
内核在完成一系列的初始化过程之后,会启动一些低权限(ring3)的进程以向我们提供用户界面
在现代操作系统中,计算机的虚拟内存空间通常被分为两块空间——供用户进程使用的用户空间(user space)与供操作系统内核使用的内核空间(kernel space)
32位下的虚拟内存空间布局如下:
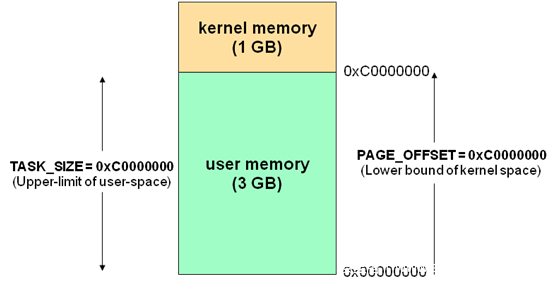
64位下的虚拟内存空间布局如下:

通俗地说,当进程运行在内核空间时就处于内核态(kernelland),而进程运行在用户空间时则处于用户态(userland),这是现代操作系统的设计者人为区分出来的设计
当我们要运行一个程序时,本质上是通过操作系统预先运行的用户态进程(如 shell 等)向操作系统发出请求,此时控制权移交内核,内核完成进程内存空间的初始化后再将控制权移交回用户进程
我们可以将操作系统理解为一个与我们的程序并行运行着的高权限程序
应用程式运行时总会经历无数次的用户态与内核态之间的转换,这是因为用户进程往往需要使用内核所提供的各种功能(如IO等),此时就需要陷入(trap)内核,待完成之后再“着陆”回用户态
这里我们讲到一个概念叫进入内核态,本质上其实是将进程的控制权限转交给操作系统内核,当内核完成其工作后控制权又重新回到用户进程
中断即硬件/软件向 CPU 发送的特殊信号,CPU 接收到中断后会停下当前工作转而执行中断处理程序,完成后恢复原工作流程
中断向量表(interrupt vector table)类似一个虚表,该表通常位于物理地址 0~1k处,其中存放着不同中断号对应的中断处理程序的地址
自保护模式起引入中断描述符表(Interrupt Descriptor Table)用以存放「门描述符」(gate descriptor),中断描述符表地址存放在 IDTR 寄存器中,CPU 通过中断描述符表访问对应门
「门」(gate)可以理解为中断的前置检查物件,当中断发生时会先通过这些「门」,主要有如下三种门:
- 中断门(Interrupt gate):用以进行硬中断处理,其类型码为 110;中断门的 DPL(Descriptor Priviledge Level)为 0,故只能在内核态下访问,即中断处理程序应当由内核激活;进入中断门会清除 IF 标志位以关闭中断,防止中断嵌套的发生
- 陷阱门(Trap gate):类型码为 111,类似于中断门,主要用以处理 CPU 异常,但不会清除 IF 标志位
- 系统门(System gate):Linux 特有门,类型码为 3、4、5、128;其 DPL 为 3,用以供用户进程访问,主要用以进行系统调用(int 0x80)
Signals机制(又称之为软中断信号)是UNIX及类UNIX系统中的一种异步的进程间通信方式,用以通知一个进程发生了某个事件,通常情况下常见的流程如下图所示:
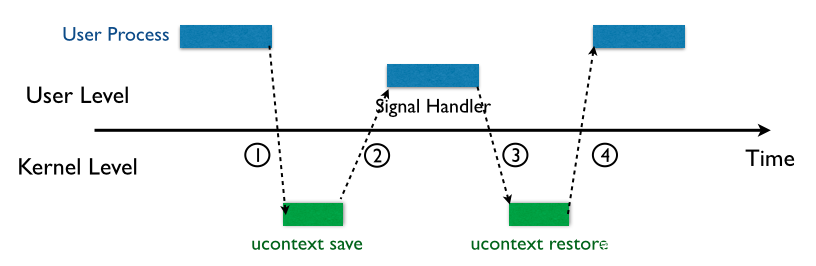
- Pre. 内核代替进程接受信号,将信号放入对应进程的信号队列中,同时将对应进程挂起,让进程陷入内核态
- ① 进程陷入内核态后,在返回用户态前会检测信号队列,若存在新信号则开始进入信号处理流程:内核会将用户态进程的寄存器逐一压入【用户态进程的栈上】,形成一个
sigcontext结构体,接下来压入 SIGNALINFO 以及指向系统调用 sigreturn 的代码,用以在后续返回时恢复用户态进程上下文;压入栈上的这一大块内容称之为一个SigreturnFrame,同时也是一个ucontext_t结构体;接下来就是内核内部的工作了 - ② 控制权回到用户态进程,用户态进程跳转到相应的 signal handler 函数以处理不同的信号,完成之后将会执行位于其栈上的第一条指令——
sigreturn系统调用 - ③ 进程重新陷入内核,通过 sigreturn 系统调用恢复用户态上下文信息
- ④ 控制权重新返还给用户态进程,恢复进程原上下文
由用户态陷入到内核态主要有以下几种途径:
- 系统调用(int 0x80/sysenter)
- 异常
- 外设产生中断
- …
通过 swapgs 切换 GS 段寄存器,将 GS 寄存器值和一个特定位置的值进行交换,目的是保存 GS 值,同时将该位置的值作为内核执行时的 GS 值使用
将当前栈顶(用户空间栈顶)记录在 CPU 独占变量区域里,将 CPU 独占区域里记录的内核栈顶放入 rsp/esp
通过 push 保存各寄存器值到栈上,以便后续“着陆”回用户态
在这里用到一个全局函数表sys_call_table,其中保存着系统调用的函数指针
由内核态重新“着陆”回用户态只需要恢复用户空间信息即可:
-
swapgs指令恢复用户态GS寄存器 -
sysretq或者iretq恢复到用户空间
三、系统调用
系统调用(system call)是由操作系统内核向上层应用程式提供的应用接口,操作系统负责调度一切的资源,当用户进程想要请求更高权限的服务时,便需要通过由系统提供的应用接口,使用系统调用以陷入内核态,再由操作系统完成请求
系统调用本质上与一般的C库函数没有区别,不同的是系统调用位于内核空间,以内核态运行
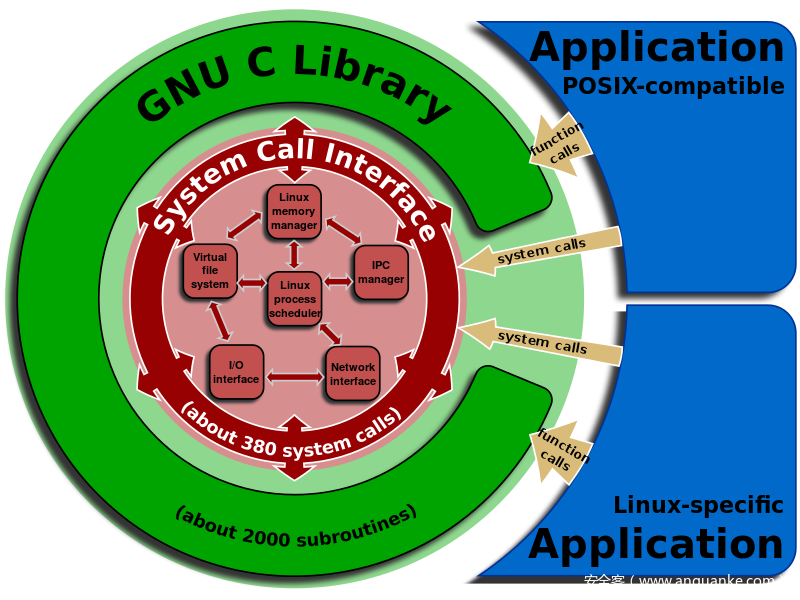
Windows系统下将系统调用封装在win32 API中,不过本篇博文主要讨论Linux
所有的系统调用被声明于内核源码arch/x86/entry/syscalls/syscall_64.tbl中,在该表中声明了系统调用的标号、类型、名称、内核态函数名称
在内核中使用系统调用表(System Call Table)对系统调用进行索引,该表中储存了不同标号的系统调用函数的地址
Linux 下进入系统调用有两种主要的方式:
- 32位:执行
int 0x80汇编指令(80号中断) - 64位:执行
syscall汇编指令 / 执行sysenter汇编指令(only intel)
接下来就是由用户态进入到内核态的流程
Linux下的系统调用以eax/rax寄存器作为系统调用号,参数传递约束如下:
- 32 位:
ebx、ecx、edx、esi、edi、ebp作为第一个参数、第二个参数…进行参数传递 - 64 位:
rdi、rsi、rdx、rcx、r8、r9作为第一个参数、第二个参数…进行参数传递
同样地,内核执行完系统调用后退出系统调用也有对应的两种方式:
- 执行
iret汇编指令 - 执行
sysret汇编指令 / 执行sysexit汇编指令(only Intel)
接下来就是由内核态回退至用户态的流程
四、进程权限管理
前面我们讲到,kernel 调度着一切的系统资源,并为用户应用程式提供运行环境,相应地,应用程式的权限也都是由 kernel 进行管理的
在内核中使用结构体 task_struct 表示一个进程,该结构体定义于内核源码include/linux/sched.h中,代码比较长就不在这里贴出了
一个进程描述符的结构应当如下图所示:
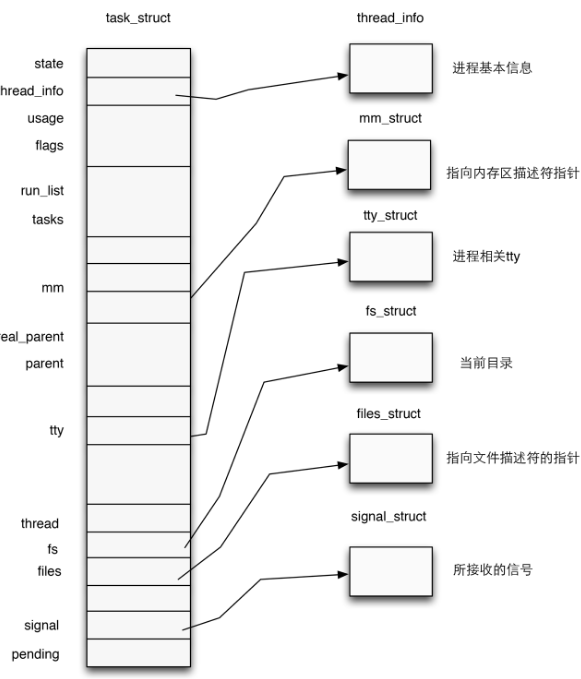
本篇我们主要关心其对于进程权限的管理
注意到task_struct的源码中有如下代码:
/* Process credentials: */
/* Tracer's credentials at attach: */
const struct cred __rcu *ptracer_cred;
/* Objective and real subjective task credentials (COW): */
const struct cred __rcu *real_cred;
/* Effective (overridable) subjective task credentials (COW): */
const struct cred __rcu *cred;
Process credentials 是 kernel 用以判断一个进程权限的凭证,在 kernel 中使用 cred 结构体进行标识,对于一个进程而言应当有三个 cred:
-
ptracer_cred:使用
ptrace系统调用跟踪该进程的上级进程的cred(gdb调试便是使用了这个系统调用,常见的反调试机制的原理便是提前占用了这个位置) - real_cred:即客体凭证(objective cred),通常是一个进程最初启动时所具有的权限
- cred:即主体凭证(subjective cred),该进程的有效cred,kernel以此作为进程权限的凭证
一般情况下,主体凭证与客体凭证的值是相同的
例:当进程 A 向进程 B 发送消息时,A为主体,B为客体
对于一个进程,在内核当中使用一个结构体cred管理其权限,该结构体定义于内核源码include/linux/cred.h中,如下:
struct cred {
atomic_t usage;
#ifdef CONFIG_DEBUG_CREDENTIALS
atomic_t subscribers; /* number of processes subscribed */
void *put_addr;
unsigned magic;
#define CRED_MAGIC 0x43736564
#define CRED_MAGIC_DEAD 0x44656144
#endif
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
unsigned securebits; /* SUID-less security management */
kernel_cap_t cap_inheritable; /* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
kernel_cap_t cap_ambient; /* Ambient capability set */
#ifdef CONFIG_KEYS
unsigned char jit_keyring; /* default keyring to attach requested
* keys to */
struct key *session_keyring; /* keyring inherited over fork */
struct key *process_keyring; /* keyring private to this process */
struct key *thread_keyring; /* keyring private to this thread */
struct key *request_key_auth; /* assumed request_key authority */
#endif
#ifdef CONFIG_SECURITY
void *security; /* subjective LSM security */
#endif
struct user_struct *user; /* real user ID subscription */
struct user_namespace *user_ns; /* user_ns the caps and keyrings are relative to. */
struct group_info *group_info; /* supplementary groups for euid/fsgid */
/* RCU deletion */
union {
int non_rcu; /* Can we skip RCU deletion? */
struct rcu_head rcu; /* RCU deletion hook */
};
} __randomize_layout;
我们主要关注cred结构体中管理权限的变量
一个cred结构体中记载了一个进程四种不同的用户ID:
- 真实用户ID(real UID):标识一个进程启动时的用户ID
- 保存用户ID(saved UID):标识一个进程最初的有效用户ID
- 有效用户ID(effective UID):标识一个进程正在运行时所属的用户ID,一个进程在运行途中是可以改变自己所属用户的,因而权限机制也是通过有效用户ID进行认证的,内核通过 euid 来进行特权判断;为了防止用户一直使用高权限,当任务完成之后,euid 会与 suid 进行交换,恢复进程的有效权限
- 文件系统用户ID(UID for VFS ops):标识一个进程创建文件时进行标识的用户ID
在通常情况下这几个ID应当都是相同的
用户组ID同样分为四个:真实组ID、保存组ID、有效组ID、文件系统组ID,与用户ID是类似的,这里便不再赘叙
前面我们讲到,一个进程的权限是由位于内核空间的cred结构体进行管理的,那么我们不难想到:只要改变一个进程的cred结构体,就能改变其执行权限
在内核空间有如下两个函数,都位于kernel/cred.c中:
-
struct cred* prepare_kernel_cred(struct task_struct* daemon):该函数用以拷贝一个进程的cred结构体,并返回一个新的cred结构体,需要注意的是daemon参数应为有效的进程描述符地址或NULL -
int commit_creds(struct cred *new):该函数用以将一个新的cred结构体应用到进程
提权
查看prepare_kernel_cred()函数源码,观察到如下逻辑:
struct cred *prepare_kernel_cred(struct task_struct *daemon)
{
const struct cred *old;
struct cred *new;
new = kmem_cache_alloc(cred_jar, GFP_KERNEL);
if (!new)
return NULL;
kdebug("prepare_kernel_cred() alloc %p", new);
if (daemon)
old = get_task_cred(daemon);
else
old = get_cred(&init_cred);
...
在prepare_kernel_cred()函数中,若传入的参数为NULL,则会缺省使用init进程的cred作为模板进行拷贝,即可以直接获得一个标识着root权限的cred结构体
那么我们不难想到,只要我们能够在内核空间执行commit_creds(prepare_kernel_cred(NULL)),那么就能够将当前进程的权限提升到root
五、I/O
*NIX/Linux追求高层次抽象上的统一,其设计哲学之一便是万物皆文件
NIX/Linux设计的哲学之一——万物皆文件,在Linux系统的视角下,无论是文件、设备、管道,还是目录、进程,甚至是磁盘、套接字等等,*一切都可以被抽象为文件,一切都可以使用访问文件的方式进行操作
通过这样一种哲学,Linux予开发者以高层次抽象的统一性,提供了操作的一致性:
- 所有的读取操作都可以通过read进行
- 所有的更改操作都可以通过write进行
对于开发者而言,将一切的操作都统一于一个高层次抽象的应用接口,无疑是十分美妙的一件事情——我们不需要去理解实现的细节,只需要对”文件”完成简单的读写操作
例如,在较老版本的Linux中,可以使用
cat /dev/urandom > /dev/dsp命令令扬声器产生随机噪声

进程文件系统(process file system, 简写为procfs)用以描述一个进程,其中包括该进程所打开的文件描述符、堆栈内存布局、环境变量等等
进程文件系统本身是一个伪文件系统,通常被挂载到/proc目录下,并不真正占用储存空间,而是占用一定的内存
当一个进程被建立起来时,其进程文件系统便会被挂载到/proc/[PID]下,我们可以在该目录下查看其相关信息
进程通过文件描述符(file descriptor)来完成对文件的访问,其在形式上是一个非负整数,本质上是对文件的索引值,进程所有执行 I/O 操作的系统调用都会通过文件描述符
每个进程都独立有着一个文件描述符表,存放着该进程所打开的文件索引,每当进程成功打开一个现有文件/创建一个新文件时(通过系统调用open进行操作),内核会向进程返回一个文件描述符
在kernel中有着一个文件表,由所有的进程共享
每个*NIX进程都应当有着三个标准的POSIX文件描述符,对应着三个标准文件流:
stdin:标准输入 - 0stdout:标准输出 - 1stderr:标准错误 - 2
此后打开的文件描述符应当从标号3起始
在*NIX中一切都可以被视为文件,因而一切都可以以访问文件的方式进行操作,为了方便,Linux定义了系统调用ioctl供进程与设备之间进行通信
系统调用ioctl是一个专用于设备输入输出操作的一个系统调用,其调用方式如下:
int ioctl(int fd, unsigned long request, ...)
- fd:设备的文件描述符
- request:请求码
- 其他参数
对于一个提供了ioctl通信方式的设备而言,我们可以通过其文件描述符、使用不同的请求码及其他请求参数通过ioctl系统调用完成不同的对设备的I/O操作
例如CD-ROM驱动程序弹出光驱的这一操作就对应着对“光驱设备”这一文件通过ioctl传递特定的请求码与请求参数完成
六、Loadable Kernel Modules(LKMs)
前面我们讲到,Linux Kernle采用的是宏内核架构,一切的系统服务都需要由内核来提供,虽然效率较高,但是缺乏可扩展性与可维护性,同时内核需要装载很多可能用到的服务,但这些服务最终可能未必会用到,还会占据大量内存空间,同时新服务的提供往往意味着要重新编译整个内核
综合以上考虑,可装载内核模块(Loadable Kernel Modules,简称LKMs)出现了,位于内核空间的LKMs可以提供新的系统调用或其他服务,同时LKMs可以像积木一样被装载入内核/从内核中卸载,大大提高了kernel的可拓展性与可维护性
常见的外设驱动便是LKM的一种
LKMs与用户态可执行文件一样都采用ELF格式,但是LKMs运行在内核空间,且无法脱离内核运行
通常与LKM相关的命令有以下三个:
-
lsmod:列出现有的LKMs -
insmod:装载新的LKM(需要root) -
rmmod:从内核中移除LKM(需要root)
CTF 比赛中的 kernel pwn 的漏洞往往出现在第三方 LKM 中,
一般来说不会真的让你去直接日内核组件
七、保护机制
与一般的程序相同,Linux Kernel同样有着各种各样的保护机制:
KASLR即内核空间地址随机化(kernel address space layout randomize),与用户态程序的ASLR相类似——在内核镜像映射到实际的地址空间时加上一个偏移值,但是内核内部的相对偏移其实还是不变的
在未开启KASLR保护机制时,内核的基址为0xffffffff81000000
内核内存布局可以参考这↑里↓
FGKASLR
KASLR 虽然在一定程度上能够缓解攻击,但是若是攻击者通过一些信息泄露漏洞获取到内核中的某个地址,仍能够直接得知内核加载地址偏移从而得知整个内核地址布局,因此有研究者基于 KASLR 实现了 FGKASLR,以函数粒度重新排布内核代码
类似于用户态程序的canary,通常又被称作是stack cookie,用以检测是否发生内核堆栈溢出,若是发生内核堆栈溢出则会产生kernel panic
内核中的canary的值通常取自gs段寄存器某个固定偏移处的值
SMAP即管理模式访问保护(Supervisor Mode Access Prevention),SMEP即管理模式执行保护(Supervisor Mode Execution Prevention),这两种保护通常是同时开启的,用以阻止内核空间直接访问/执行用户空间的数据,完全地将内核空间与用户空间相分隔开,用以防范ret2usr(return-to-user,将内核空间的指令指针重定向至用户空间上构造好的提权代码)攻击
SMEP保护的绕过有以下两种方式:
- 在设计中,为了使隔离的数据进行交换时具有更高的性能,隐性地址共享始终存在(VDSO & VSYSCALL),用户态进程与内核共享同一块物理内存,因此通过隐性内存共享可以完整的绕过软件和硬件的隔离保护,这种攻击方式被称之为
ret2dir(return-to-direct-mapped memory ) - Intel下系统根据CR4控制寄存器的第20位标识是否开启SMEP保护(1为开启,0为关闭),若是能够通过kernel ROP改变CR4寄存器的值便能够关闭SMEP保护,完成SMEP-bypass,接下来就能够重新进行ret2usr
KPTI即内核页表隔离(Kernel page-table isolation),内核空间与用户空间分别使用两组不同的页表集,这对于内核的内存管理产生了根本性的变化
KPTI 机制的出现使得 ret2usr 彻底成为过去式
0x01.Linux Kernel 简易食用指南
Pre.安装依赖
环境是Ubuntu20.04
$ sudo apt-get update
$ sudo apt-get install git fakeroot build-essential ncurses-dev xz-utils qemu flex libncurses5-dev fakeroot build-essential ncurses-dev xz-utils libssl-dev bc bison libglib2.0-dev libfdt-dev libpixman-1-dev zlib1g-dev libelf-dev
一、获取内核镜像(bzImage)
大概有如下三种方式:
- 下载内核源码后编译
- 直接下载现成的的内核镜像,不过这样我们就不能自己魔改内核了2333
- 直接使用自己系统的镜像
前往Linux Kernel Archive下载对应版本的内核源码
笔者这里选用5.11这个版本的内核镜像
$ wget https://cdn.kernel.org/pub/linux/kernel/v5.x/linux-5.11.tar.xz
解压我们下载来的内核源码
$ tar -xvf linux-5.11.tar.xz
完成后进入文件夹内,执行如下命令开始配置编译选项
$ make menuconfig
进入如下配置界面

保证勾选如下配置(默认都是勾选了的):
- Kernel hacking —-> Kernel debugging
- Kernel hacking —-> Compile-time checks and compiler options —-> Compile the kernel with debug info
- Kernel hacking —-> Generic Kernel Debugging Instruments —> KGDB: kernel debugger
- kernel hacking —-> Compile the kernel with frame pointers
一般来说不需要有什么改动,直接保存退出即可
运行如下命令开始编译,生成内核镜像
$ make bzImage
可以使用make bzImage -j4加速编译
笔者机器比较烂,大概要等一顿饭的时间…
以及编译内核会比较需要空间,一定要保证磁盘剩余空间充足
笔者在编译 4.4 版本的内核时出现了如下错误:
cc1: error: code model kernel does not support PIC modemake[1]: *** No rule to make target 'debian/canonical-certs.pem', needed by 'certs/x509_certificate_list'. Stop这个时候只需要在Makefile文件中:
KBUILD_CFLAGS的尾部添加选项-fno-pieCC_USING_FENTRY项添加-fno-pic以及在
.config文件中找到这一项,等于号后面的值改为""
最后又出现了一个错误…笔者实在忍不了了,换到Ubuntu 16进行编译…一遍过…
出现这种情况的原因主要是高版本的 gcc 更改了内部的一些相关机制,
只需要切换回老版本gcc即可正常编译
完成之后会出现如下信息:
Kernel: arch/x86/boot/bzImage is ready (#1)
在当前目录下提取到vmlinux,为编译出来的原始内核文件
$ file vmlinux
vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, BuildID[sha1]=f1fc85f87a5e6f3b5714dad93a8ac55fa7450e06, with debug_info, not stripped
在当前目录下的arch/x86/boot/目录下提取到bzImage,为压缩后的内核文件,适用于大内核
$ file arch/x86/boot/bzImage
arch/x86/boot/bzImage: Linux kernel x86 boot executable bzImage, version 5.11.0 (root@iZf3ye3at4zthpZ) #1 SMP Sun Feb 21 21:44:35 CST 2021, RO-rootFS, swap_dev 0xB, Normal VGA
zImage—是vmlinux经过gzip压缩后的文件。
bzImage—bz表示“big zImage”,不是用bzip2压缩的,而是要偏移到一个位置,使用gzip压缩的。两者的不同之处在于,zImage解压缩内核到低端内存(第一个 640K),bzImage解压缩内核到高端内存(1M以上)。如果内核比较小,那么采用zImage或bzImage都行,如果比较大应该用bzImage。https://blog.csdn.net/xiaotengyi2012/article/details/8582886
据说大二下的操作系统实验里就有这个…不过笔者的寒假还没放完呢233333
以及请先阅读完「0x01.四 」之后再回来看本节内容~
在arch/x86/entry/syscalls/syscall_64.tbl中添加我们自己的系统调用号,这里用笔者个人比较喜欢的数字114514
114514 64 arttnba3_test sys_arttnba3_test
在include/linux/syscalls.h中添加如下函数声明:
/* for arttnba3's personal syscall test */
asmlinkage long sys_arttnba3_test(void);
在kernel/sys.c中添加如下代码(放置于最后一行的#endif /* CONFIG_COMPAT */之前):
SYSCALL_DEFINE0(arttnba3_test)
{
printk("arttnba3\'s personal syscall has been called!\n");
return 114514;
}
这里的SYSCALL_DEFINE0()本质上是一个宏,意为接收0个参数的系统调用,其第一个参数为系统调用名
笔者定义了一个简单的输出一句话的系统调用,在这里使用了内核态的printk()函数,输出的信息可以使用dmesg进行查看
这一步参照之前的步骤即可,通过这一步我们要将我们自己的系统调用编译到内核当中
我们使用如下的例程测试我们的新系统调用
#include <unistd.h>
int main(void)
{
syscall(114514);
return 0;
}
编译,放入磁盘镜像中后重新打包,qemu起内核后尝试运行我们的例程,结果如下:
因为dmesg输出的东西太多,这里还附加用了grep命令过滤

可以看到,我们的系统调用arttnba3_test被成功地嵌入了内核当中,并成功地被测试例程所调用,撒花~