二进制分析从工具说起
二进制分析从工具说起
作者:Anciety
前言
二进制分析很难,我从一开始就这样觉得,因为好多二进制分析的基础问题现在也还处于正在研究的阶段。
但是它又是这么有吸引力,可能每一个曾拆过闹钟、手表、电视机的二进制研究者都能在二进制分析中找到曾经的那种乐趣,去回答自己“为什么”的乐趣,至少我还是很享受的。
同时,作为一个”工具“狂热者,我总喜欢去了解自己所使用的工具。
我还记得在我第一次使用 IDA 的 F5 的时候,感觉自己打开了新世界的大门,好像二进制分析一下简单了,
虽然后续的经历告诉我光有 F5 还是不够的,但是对反编译的执着是从那个时候开始的。
反编译,作为二进制分析的基础功能,帮无数二进制研究者节约了无数的时间,但是在反编译之后,都发生了什么事情?
二进制分析在研究什么?
可能并不是所有人都知道。
这一篇我将作为引入,讲一些二进制分析的基础问题,后续可能还会有更深入的问题,希望能够给大家一定的帮助。
二进制分析为什么不一样
首先让我们来问一个问题,二进制分析到底有什么不一样的?
这个问题的答案并不困难,很简单,只是因为我们所接触到的是“机器代码”,也就是二进制文件。
如果分析的内容不是二进制呢?比如,是代码?那么有什么不一样呢?
要我看,其实没什么不一样的,国内的 CTF 同学们喜欢区分自己是 web 手,二进制选手,我觉得都一样。
如果 web 手碰到的是 JAR 文件,他同样也会变为 “二进制” 手,二进制选手碰到 ELF 中的 http server ,同样也是 web 手,没那么多不一样的。
如果真的有什么不一样的,我觉得,大概是二进制研究者们对机器代码的执着吧。
那么,我们就从机器代码说起。
机器代码
机器代码,由机器执行的代码,最终也是代码,区别就在于其内容是“二进制”,这也是“二进制分析”这个说法的由来,因为我们所分析的是机器代码。
既然机器代码是我们的核心,那么我们可以好好思考下机器代码本身。
其实机器代码背后的故事是有完善数学理论支持的,不过我知道,大部分同学应该都没怎么接触过,因为我们崇尚在实践中学习嘛,这很正常。
实践能够帮助大家“熟悉”,熟悉是学习的重要过程,熟悉之后,才能走向下一步。
所以怎么理解机器代码,或者说怎么理解机器呢?
我们可以这么想,机器,包括“状态”和指令,指令负责改变状态。
在 x86 里,状态都有什么?寄存器、内存,都是状态,指令则是我们通常所理解的指令,也就是汇编指令,每一条汇编指令都可以造成状态的改变,不管是寄存器的值变了或者是内存的值变了,很简单,对吧?
汇编指令和机器指令本身就几乎是一一对应的,将机器指令变成汇编语言的过程就像是查表然后得到答案,我们看不懂机器指令,因为很难记住巨大的表,但是我们可以看懂汇编指令嘛。
所以二进制分析的第一步,就是将机器指令翻译成汇编指令。
从机器指令到汇编指令
这是一个简单的事情,但是又带来了很多麻烦。
是的,刚进入二进制分析的第一步我们就碰到了麻烦。
麻烦的点在哪呢?在于,这个表太大了,并不是那么简单的“1-1对应”。
举个例子,我们现在有这么一条指令:0x00 0x10 0x00 0x00 0x00,这条指令的意思假设是jmp 0x10。
很明显,第二个字节的内容是说,需要跳转的目标地址。
第二个字节不大可能利用查表来判断目标地址,这很显然,不然这个表会非常大,而且大得没有意义,因为如果我们知道在第一个字节的0x00代表着jmp,那么后续的 4 个字节就一定是一个地址,直接转换成地址数字就好了。
所以,我们怎么转换呢?
聪明的小伙伴们肯定都想到办法了,当然是……写个程序啦。
事实上许多反汇编的软件都是这么干的,通过写程序,我们可以按照机器代码的规则,读取出当前的机器代码应该是什么操作,然后取出这些机器代码中的“数据”部分,例如刚才jmp 0x10例子中的0x10。
能够这样做的原因是因为机器代码是有规则的,例如 ARM 指令集中的机器代码:
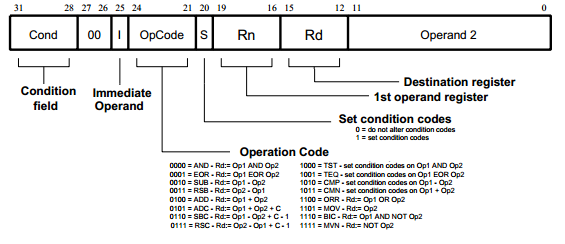
这是 ARM 中数据处理指令的格式,也就是“规则”,可以看到,其中指令被分为了许多部分,每一个部分都有自己含义。
这么看,似乎这个转换变得简单了,我们按照相应的规则进行转换就好了,如果……所有的指令都像是 ARM 的指令一样的话。
这个转换简单的原因在于,ARM 指令的大小是固定的,所以机器指令中,每一个部分都是确定的,那么获取其实很简单。
我们知道,ARM 叫做定长指令集,还有一种,叫做变长指令集,例如有名的,x86。
让我们来看看 x86 的指令大概是什么样的:
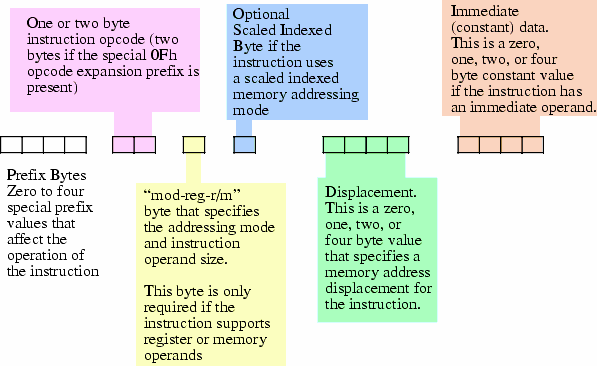
乍一看似乎并没觉得复杂了多少,但是如果仔细读,你会发现好多 “Optional" 、 "Or" 之类的词语,这就是复杂的根源。
x86 的指令集由于长度不固定,经常需要一边查看指令是什么一边决定下一个 “部分” 在哪个位置,这就给这样的转换带来了复杂度。
另外,复杂度的另一方面来源于,虽然我们现在所看到的指令似乎都不是很复杂,但是指令集是在不断扩展的,
根据硬件发展的实际需求,指令集也在不断扩展,导致指令变得越来越多,那么我们所写的程序也就变得越来越复杂……
总有一天,这个程序会大到所有人都没有心思去看,bug 修起来也十分费劲。
这个问题有什么解决方法吗?有的,我们一会再聊。
之后,还有语义
好了我们知道了一个麻烦了,然而事情依然没有这么简单。
假设我们获取到了汇编代码了,然后呢?我们接下来怎么做?
看看 IDA 做了什么,这个时候, IDA 会提供给我们一个图,让我们能看到汇编的执行流,比如跳转会到哪个块对吧?
这个图,控制流图,需要分析获取到。
先不用提其他内容了,就以这个控制流图的获取为例吧,我们现在有了汇编代码了,如何变成这个图呢?
得到这个图,我们需要知道哪些指令是跳转,因为每个跳转都应该跳到一个块的开始位置,观察观察 IDA 我们就可以发现这个规律,每个跳转都是到一个块的开始位置的。
所以问题变成了如何知道哪些指令是跳转。
这有何难?每个指令集是跳转的就那么些,不多啊。
确实,如果只看一个指令集,似乎确实没那么多,但是,这么多指令集呢。。。
难道我们真的需要一个指令一个指令去指定哪些是跳转指令吗?
注意,我们现在去找到跳转指令,也只是为了给获取控制流图用的,换句话说,如果另外的一个需求,我们需要的不是知道所有的跳转指令了,而是需要知道所有的赋值指令,以及它们都分别赋值了什么内容给什么寄存器呢?
如果每一个指令集,我们都这样去做,事情就很复杂了,工作量太大了。
所以聪明的人们想到,我们可以发明一个指令集,然后把其他指令集都翻译过去。
这个指令集,就叫做中间语言。
中间语言本身并不是真实的指令集,但是它也像一个指令集一样,只是不需要遵循硬件的设计,我们把其他的指令集的“意思”都转换到这个中间语言指令集上,然后所有的分析,都只需要在这个中间语言上写一份了。
这样做确实降低了工作量,但是问题在于,翻译到中间语言本身,依然是巨大的工作量。。
ghidra 的解决方案
现在我们落实了两个工作量巨大的问题,这两个问题其实困扰着许多的二进制分析软件。
大多数的工具采用了更原始的方法来解决这个问题,那就是,一把梭。
直接不管这些,上手就是写,管他呢,只要能写出来对吧,道理倒也没错,也确实可行,但是……
让我们来,看个例子:
https://github.com/falconre/falcon/blob/master/lib/translator/x86/semantics.rs
这是一个二进制分析框架,仅处理翻译中间语言的部分代码,单个 4k 行的文件总是让人望而生畏,这还是在并不是从二进制直接翻译过来的基础上做的。
然而 ghidra
(https://github.com/NationalSecurityAgency/ghidra) 找到了更好的方案。
其实这个方案很早就提出了,只不过是从学术界开始的,但是 ghidra 确实将其用到了实际项目中。
这个思路其实也并不复杂,那就是,发明一门语言,专门用于描述二进制是怎么变成汇编语言和中间语言的。
通过这样的方式,两个事情合二为一,同时由于语言只用于做这个事情,专门性更高,代码量就会相应降低一些,更好维护了。
ghidra 发明的语言,叫做sleigh
(https://ghidra.re/courses/languages/html/sleigh.html)。
Sleigh 语言
Sleigh 语言的语法比较奇怪,限于篇幅,只能大致介绍一下设计的思路,后续或许会专门讲解一下 Sleigh 语言。
认识 sleigh 的同时还需要认识 pcode ,也就是 sleigh 语言所对应的中间语言。
pcode 的设计有几点需要提及:
1.无论寄存器还是内存,都被当作平坦的(或者说,线性的)空间,也就是,把寄存器也当成内存来看
2.操作在 varnode 上完成,也就是 varnode 即程序的操作单位, varnode 中指定了空间、在空间中的偏移和大小
这样说可能不太好理解,让我们举例说明。
首先是关于空间,假设我们有 10 个寄存器,分别是r0到r9,那么我们可以定义一个空间,叫做寄存器空间,然后,让r0对应空间中地址(偏移)为 0 的内容,如果寄存器大小是 4 个字节,那么r1就位于偏移 4 ,依此类推。
至于 varnode ,比如一条指令是add r0, r1,也就是r0 += r1,那么对这条指令的理解就是,寄存器空间中,偏移为 0 的 4 个字节中的内容,加上寄存器空间中偏移为 4 的 4 个字节中的内容。
如下图:
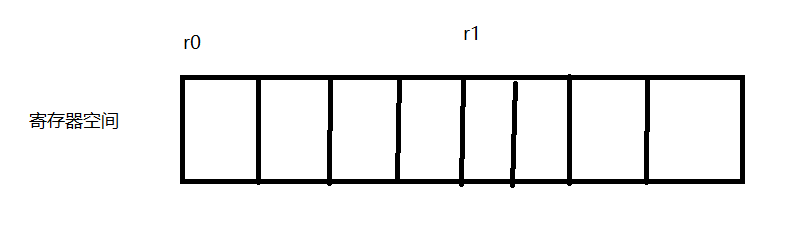
为什么需要这么设计呢?
这是因为寄存器可能存在交叉的情况,例如在 x86 下,rax中包含了eax、ax等,如果都当作内存来看,那么就比较简单了,rax如果是 0 开始,大小为 8 ,那么eax就是 0 开始,大小为 4 。
这样所有的交叉都便于处理了。包含关系容易解决。
而 Sleigh 语言所需要做的事情,包括两个部分:
1.指定二进制字节串如何变为汇编语言
2.指定二进制字节串如何变为 pcode 中间语言
两者可以合并,所以 Sleigh 就将他们合并了,也就是,指定二进制字节串如何变为汇编语言和 pcode 。
如何指定呢?机器代码既然存在自己的规则,存在 “部分” ,那么就可以将其进行拆解,换句话说,部分和总体就存在包含关系,这样的包含关系就可以形成一个树形结构:
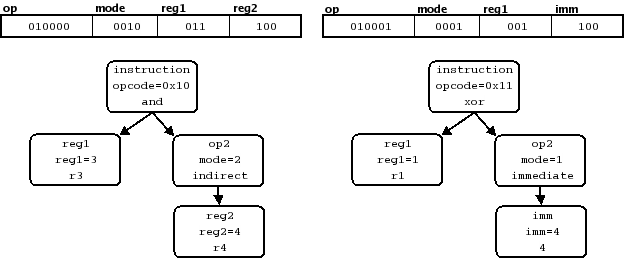
之后,分别指定树上每个节点如何显示(也就是,指定如何变为汇编语言),以及 pcode 是什么,就可以得到两棵树:
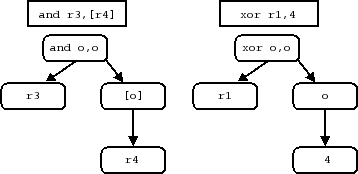
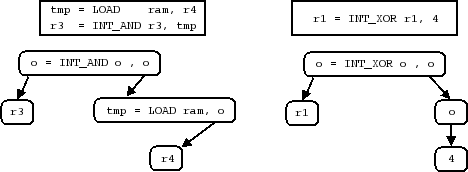
通过递归的方式将两棵树上节点的内容组合起来,就同时得到了汇编语言和 pcode 中间语言。
至于指定字节串和树之间的关系,Sleigh 将每一个“部分”进行了定义,在执行 Sleigh 语言的时候,就可以知道每一个部分具体的值是多少。
例如在一开始的树型结构中,Sleigh 定义的“部分”,这些部分包括opcode、reg1和op2。
而op2则又包含一个部分,这个部分既可以是reg2也可以是imm。
op2到底是reg2还是imm呢?这就是指定二进制字符串如何变为树的关键,Sleigh 语言中,可以通过指定一些约束,也就是,“当什么情况发生的时候,应该选择什么”,来决定如何变为树。
在这里的例子里,当mode == 2的时候,op2包含的就是reg2,而当mode == 1的时候,包含的就是imm。
通过这样的方式,我们只需要维护由 Sleigh 语言编写的程序。
而 Sleigh 语言除了指定如何进行翻译之外,并不负责别的事情,所以其语言是针对性的进行精简的,这样的程序就可以既不损失所需要的功能,又尽可能的短小。
这样的语言我们称作“领域特定语言”(DSL, Domain Specific Language),在很多领域都有这样的例子。
例如,表示网页的内容如果用其他语言编程不方便,所以我们发明了 HTML ,思考一下,是不是用其他语言“构造” HTML 的时候挺复杂,但是直接编写 HTML 就比较简单呢?
同样的道理,Sleigh 语言降低了维护难度。
Ghidra 的问题
有一说一,Ghidra 在某些方面其实相当先进,至少从利用 Sleigh 的点上,我觉得就比 IDA 的实现方式更好。
但是由于一开始 Ghidra 就作为完整工具考虑设计的,所以在二次开发上,Ghidra 并不是很友好,这和 IDA 很相似。
IDA 本身作为逆向工具很好用,但是其 API 就非常麻烦。
Ghidra 使用了 Java ,由于 Java 是具备虚拟机的语言,API 的调用难度已经大大降低了,但是如果想要脱离开进行二次开发(例如在 Ghidra 的 Sleigh 基础上编写其他二进制分析工具或者逆向工具)就变得不那么方便了。
好在,Ghidra 的反编译器其实是脱离开其 Java 层的,采用了 C++ 开发,并且提供了良好的 API 。
BinCraft
BinCraft (https://github.com/ret2lab/bincraft)
其实很久以前我就想试试写二进制分析相关的工具了,但是似乎一直在纠结技术路线,没有动手,这次算是终于走出了一步。
BinCraft算是我斟酌了好久终于选定的路线吧,将 Ghidra 的反编译器引入,来做 Sleigh 的翻译,目前提供了 Rust 和 Python 的接口,并且核心接口其实在 Rust 层。
这样做有几个目的,一来方便了二次开发,Rust 的 API 使用难度总是比 Cpp 或者 C 好很多,二来之后的其他功能可以直接在 Rust 层实现。
为什么要在 Rust 层实现呢?因为这样不会引入虚拟机,也就是说,可以像用 C 一样用 Rust 的东西。
后续 BinCraft 将会进一步地成长为完整的二进制分析的框架,我们会继续提供二进制分析的算法(例如 CFG 、控制流图等)、一些开箱即用的分析(变量定义分析等),甚至我希望能够具备通用的、分层的反编译器,还希望有模拟器(类似 unicorn)等。
通过 BinCraft ,希望二进制分析的自动化能够变得更容易,既对于逆向人员来说,更容易编写脚本,也对于开发者来说,更容易编写程序提供给逆向人员使用。
总之,希望复杂的二进制分析,能够在一个又一个工具的帮助下,变得更加简单。
