验证码与人工智能的激荡二十年:成为对手
验证码与人工智能的激荡二十年:成为对手
在上篇中,我们介绍了验证码在2000年左右时诞生,而人工智能在平行世界中已经发展了40多年。作为验证码(CAPTCHA)概念的提出者,Luis von Ahn 认为 CAPTCHA 的设计应该基于尚未解决的人工智能难题[1],具体到字符验证码而言,当时面对的主要挑战就是 OCR(Optical Character Recognition,光学字符识别)。
因此,实际开发出的验证码一般是加入了干扰之后的字符,OCR技术难以识别,而人类则可以比较轻易地在众多干扰中准确地认出完整的词汇或者字符序列,这也符合CAPTCHA中「人类可以轻易通过,但是很难写出一个程序达到较高通过率」的定义。例如2001 年Luis von Ahn和雅虎(Yahoo)网站合作开发出 EZ-Gimpy 字符验证码就长这样: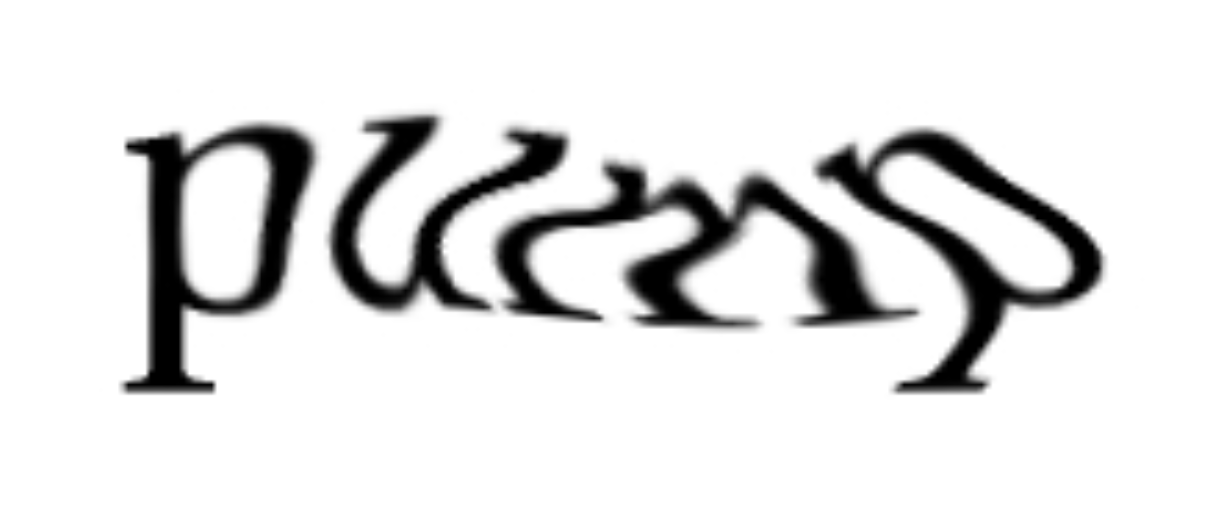
也就是说,早在验证码刚诞生的时候,就不得不面对人工智能这个对手,特别是已经发展多年的OCR技术。因此,本文首先简要介绍OCR技术,随后会重点去阐述OCR技术原理中经典的Shape context算法,最后回到现实中的对抗情况,客观分析当时OCR技术对字符验证码的破解识别情况。
一、OCR 简介
OCR 是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程[2]。其历史最早可以追溯到电报时代,同时其在帮助视力障碍人士阅读等方面的应用也极大地推动了早期 OCR 技术的进步。发展到现在,OCR 更多的是模式识别,人工智能和计算机视觉的综合研究领域。
 而在字符验证码诞生之初的 2000 年左右,那时的 OCR 的主流实现手段在现在看来还比较简单,比较有代表性的有基于卷积神经网络(convolutional neural networks)的 LeNet[3]、基于支持向量机(support vector machines)的[4][5],以及下面将要重点介绍的经典计算机视觉算法「形状上下文」(shape context)[6]等,这也是最早用于识别字符验证码的 OCR 算法之一。
而在字符验证码诞生之初的 2000 年左右,那时的 OCR 的主流实现手段在现在看来还比较简单,比较有代表性的有基于卷积神经网络(convolutional neural networks)的 LeNet[3]、基于支持向量机(support vector machines)的[4][5],以及下面将要重点介绍的经典计算机视觉算法「形状上下文」(shape context)[6]等,这也是最早用于识别字符验证码的 OCR 算法之一。
二、Shape Context 算法
2.1 算法原理
Shape Context 是一种描述物体形状的方法,用于测量形状之间的相似度以及复原形状上点之间的对应关系,因此该算法天然地就可以用来完成 OCR 任务:计算出已知字符和待识别形状的 shape context,通过比对 shape context 之间的距离找到最有可能的形状和字符对应关系,从而达到识别字符的目的。
算法的基本思路如下:
算法的思路看起来并不复杂,而且每一步的具体实现都在论文中解释得很清楚: 
最后,下图简要描述了 shape context 的计算和匹配过程。
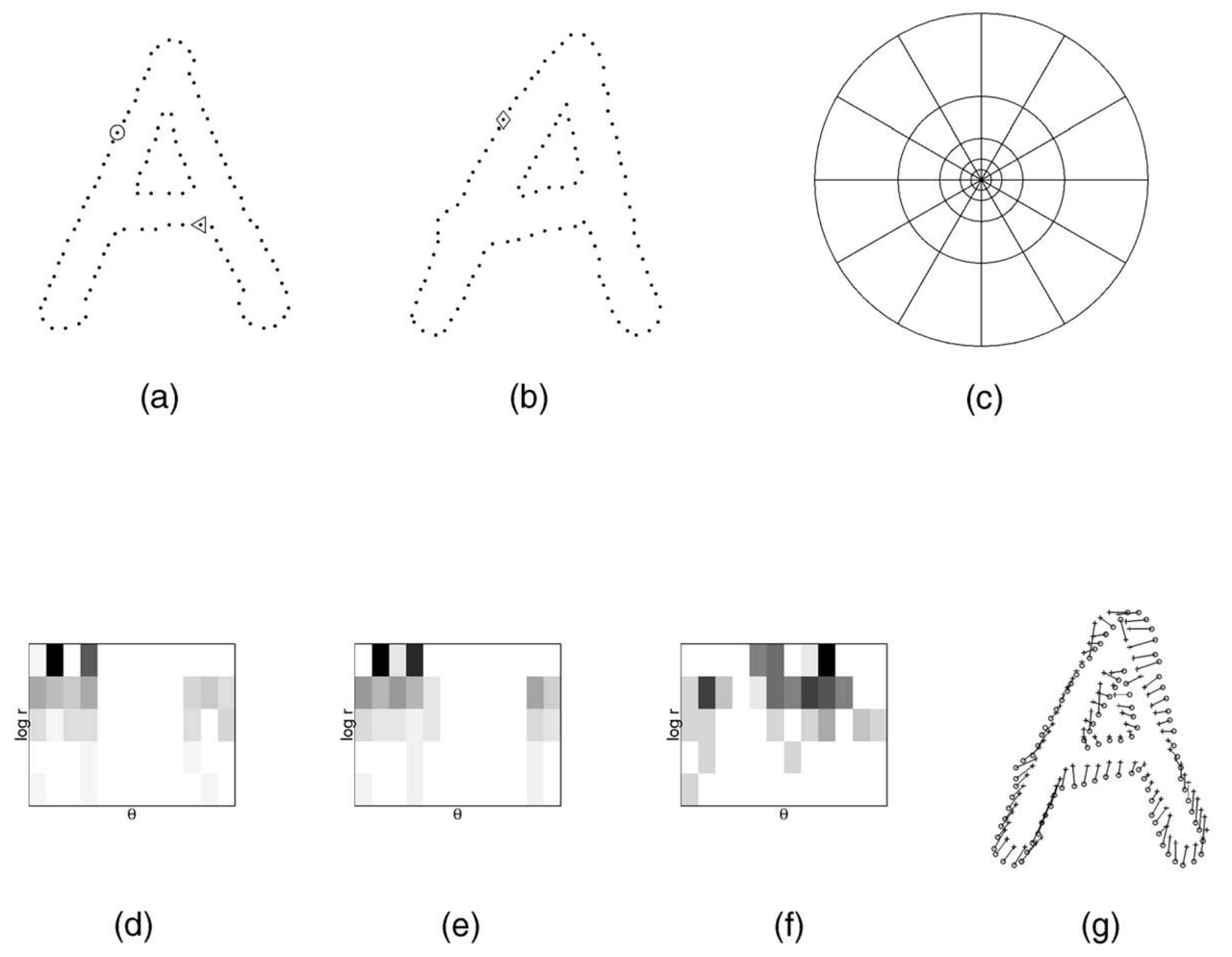

2.2 代码实现
这里结合一份开源的 shape context 的 Python 实现[7]对算法细节和匹配效果做个演示: - 设置对数极坐标系角度(弧度)和半径的切分参数(按照论文的预设值):
nbins_r=5 nbins_theta=12 r_inner=0.1250 r_outer=2.0
- 计算每个点间的距离,并标准化。计算出距离最远的两个点以备后用:
t_points = len(points) # distance r_array = cdist(points, points) # getting two points with maximum distance to norm angle by them # this is needed for rotation invariant feature am = r_array.argmax() max_points = [am / t_points, am % t_points] # normalizing r_array_n = r_array / r_array.mean()
- 把距离切分 bin 并计算区间内点出现的次数:
r_bin_edges = np.logspace(np.log10(r_inner), np.log10(r_outer), nbins_r)
r_array_q = np.zeros((t_points, t_points), dtype=int)
# summing occurences in different log space intervals
# logspace = [0.1250, 0.2500, 0.5000, 1.0000, 2.0000]
# 0 1.3 | -> 1 0 | -> 2 0 | -> 3 0 | -> 4 0 | -> 5 1
# 0.43 0 | 0 1 | 0 2 | 1 3 | 2 4 | 3 5
for m in xrange(self.nbins_r):
r_array_q += (r_array_n r_bin_edges[m]- 计算每个点之间的角度,标准化,然后都变换到 0 - 2π 的区间:
theta_array = cdist(points, points, lambda u, v: math.atan2((v[1] - u[1]), (v[0] - u[0]))) norm_angle = theta_array[max_points[0], max_points[1]] # making angles matrix rotation invariant theta_array = (theta_array - norm_angle * (np.ones((t_points, t_points)) - np.identity(t_points))) # removing all very small values because of float operation theta_array[np.abs(theta_array) 1e-7] = 0 # 2Pi shifted because we need angels in [0, 2Pi] theta_array_2 = theta_array + 2 * math.pi * (theta_array 0)
- 把角度切分 bin 并计算区间内点出现的次数:
theta_array_q = (1 + np.floor(theta_array_2 / (2 * math.pi / self.nbins_theta))).astype(int)
- 对每个半径和角度区间的点进行计数,得到 shape context 描述符:
fz = r_array_q > 0
nbins = self.nbins_theta * self.nbins_r
descriptor = np.zeros((t_points, nbins))
for i in xrange(t_points):
sn = np.zeros((self.nbins_r, self.nbins_theta))
for j in xrange(t_points):
if (fz[i, j]):
sn[r_array_q[i, j] - 1, theta_array_q[i, j] - 1] += 1
descriptor[i] = sn.reshape(nbins)其他部分结合论文都很好理解,这里只解释两个有可能被忽略但是非常重要的点:
1) r_array_n = r_array / r_array.mean() 这一句的作用是把所有的距离都标准化,标准化的方式是转换为这个距离相对于平均距离的比值。也就是 r_array 是轮廓上每个点之间的欧氏距离,是绝对值;r_array_n 是转换之后的比值矩阵,是相对值: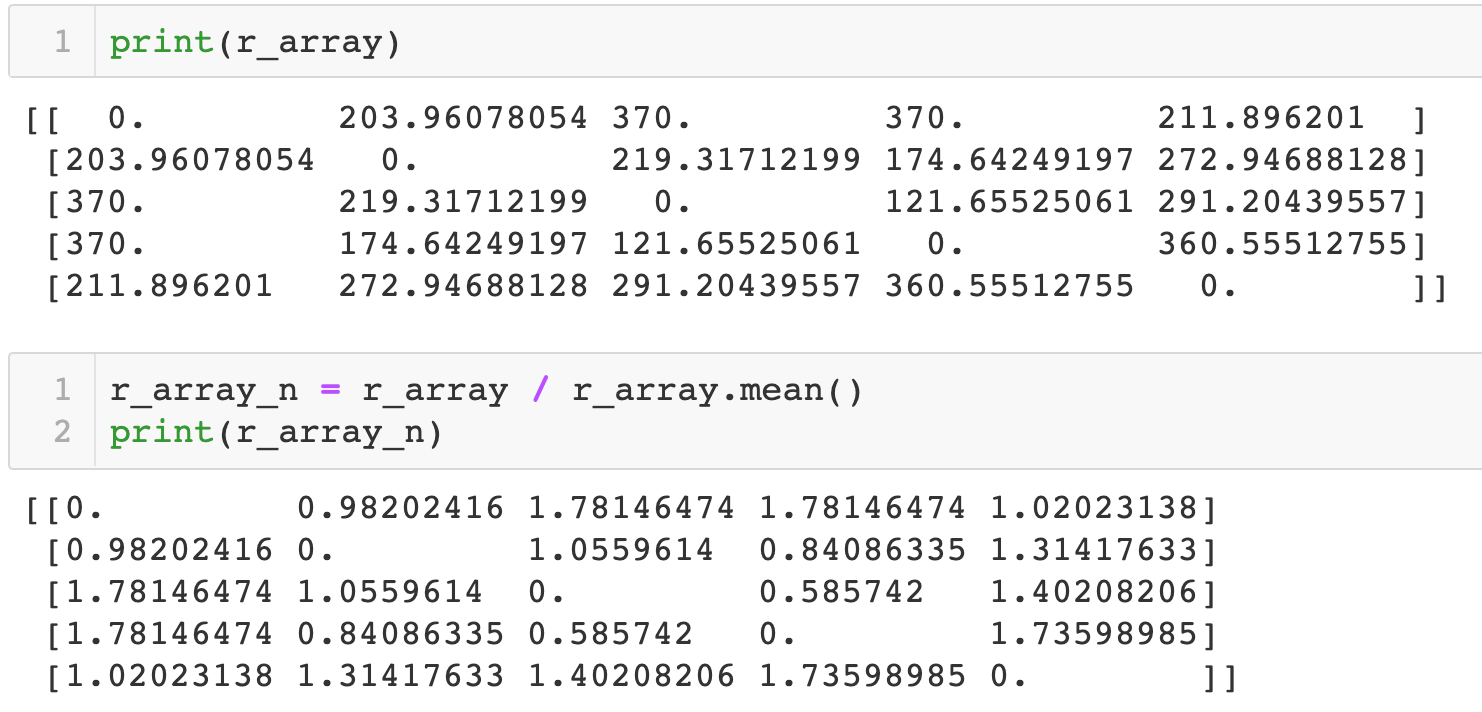
这样做的目的是使 shape context 具有缩放不变性,也就是同一个物体的不同尺寸的图像,计算出的 shape context 是相同的。
2)theta_array = (theta_array - norm_angle * (np.ones((t_points, t_points)) - np.identity(t_points))) 这里的作用和上面类似,使 shape context 具有旋转不变性(因为所有的角度都是相对于距离最远的两个点之间的连线表示的,这也是为什么第二步要找出所有点里距离最远的一对)。
基于以上实现的 shape context 算法,下面的代码演示了一个最简单的利用该算法进行 OCR 识别的过程。可以看到,在识别毫无干扰的数字图片时的效果是很准确的。
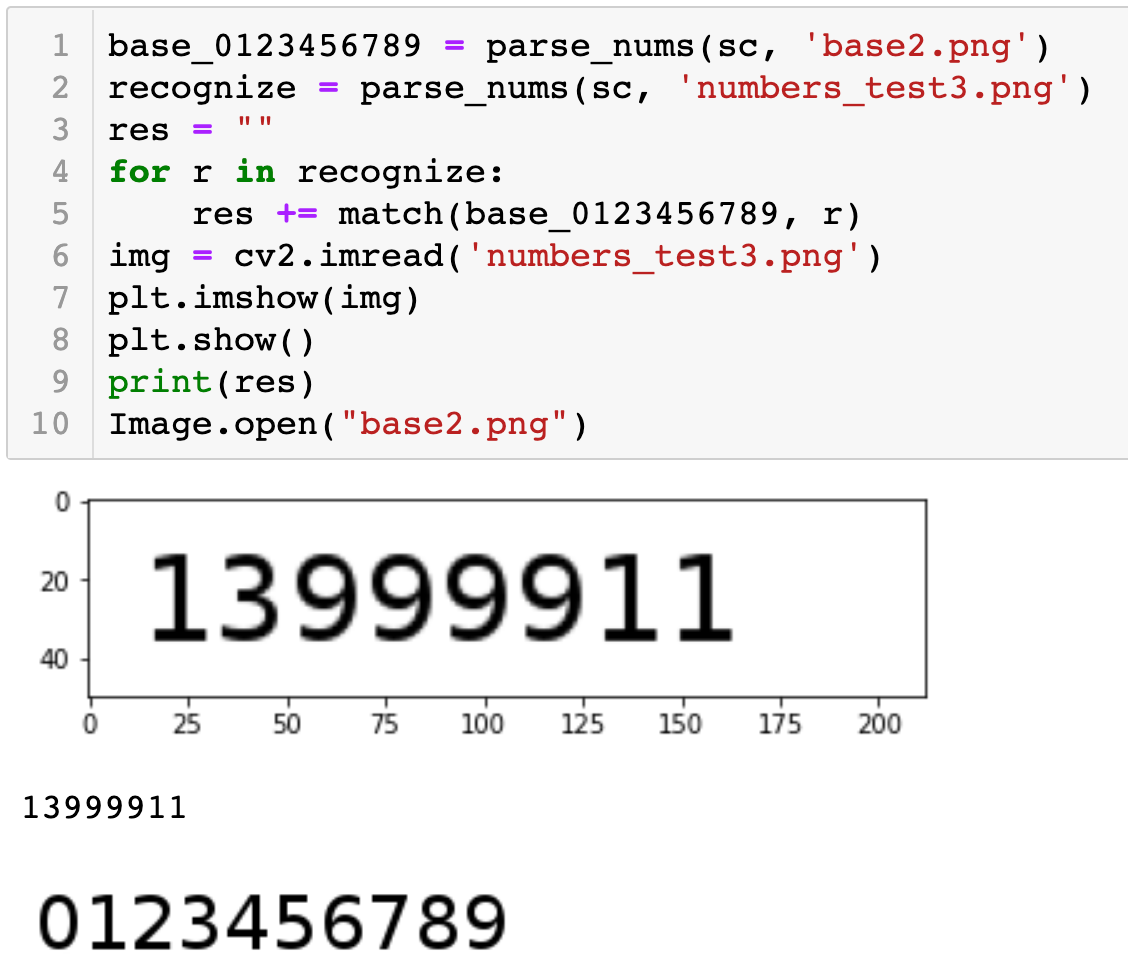
然而对于使用 iPad 手写的数字的识别,识别准确率还是很低的,如下所示:
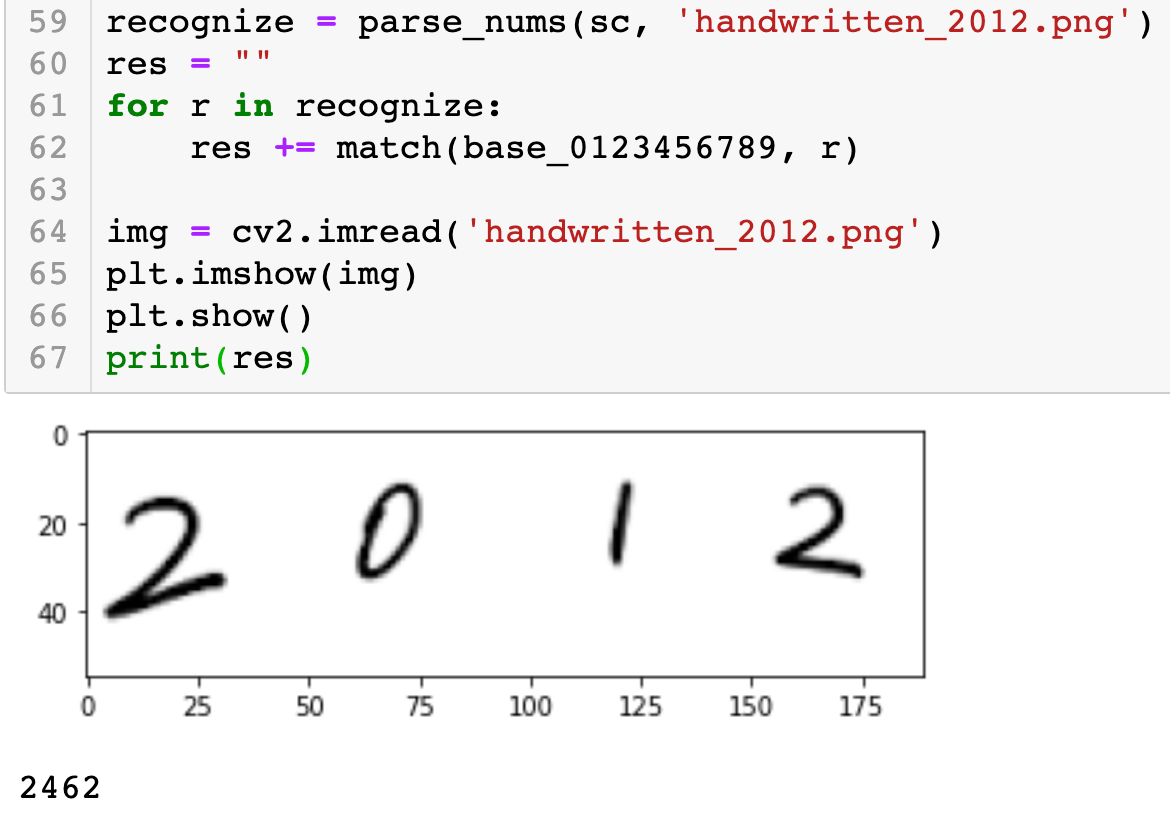
最后,对于 shape context 论文作者而言,他当时利用 MNIST 数据集进行测试,可以达到0.63%的错误率,是当时的最好成绩[6],不过那是建立在大量训练集的基础上。
三、OCR 技术的识别效果
有利益的地方就有对抗,字符验证码诞生不久,就出现了很多对其安全性进行评估的研究。这里以 2003 年 Greg Mori 等人的尝试[8]为例,说明一下当时取得的进展。
Greg 等人研究的目标是在存在对抗性干扰的背景中进行物体识别,识别字符验证码的正确答案就是这类任务一个很好的例子。他们选取的目标就是上面介绍过的 Gimpy 和 EZ-Gimpy,采用的识别算法的核心也是上面重点介绍的 shape context 算法的变体,在 EZ-Gimpy 数据集和 Gimpy 数据集上分别达到 93% 和 33%的通过率。他们使用了之前在[9]中提出的两阶段的物体识别方法:
1. 快速修剪(Fast pruning):在大量可能的候选形状(candidate shapes)中取出一个较小的子集
2. 详细匹配(Detailed matching):在较小的子集上进行耗时但是精确的详细匹配
其中在形状匹配的时候作者使用的是 shape context 算法的一个变体:
![]()

这个转换的原因也比较好理解,现在 bin 里的值不是一个标量而是一个向量。
论文中的这种形状描述符称为「泛化的形状上下文」(generalized shape contexts)。
看一下利用这种形状匹配算法使准确率达到 93% 的 EZ-Gimpy 的识别过程: 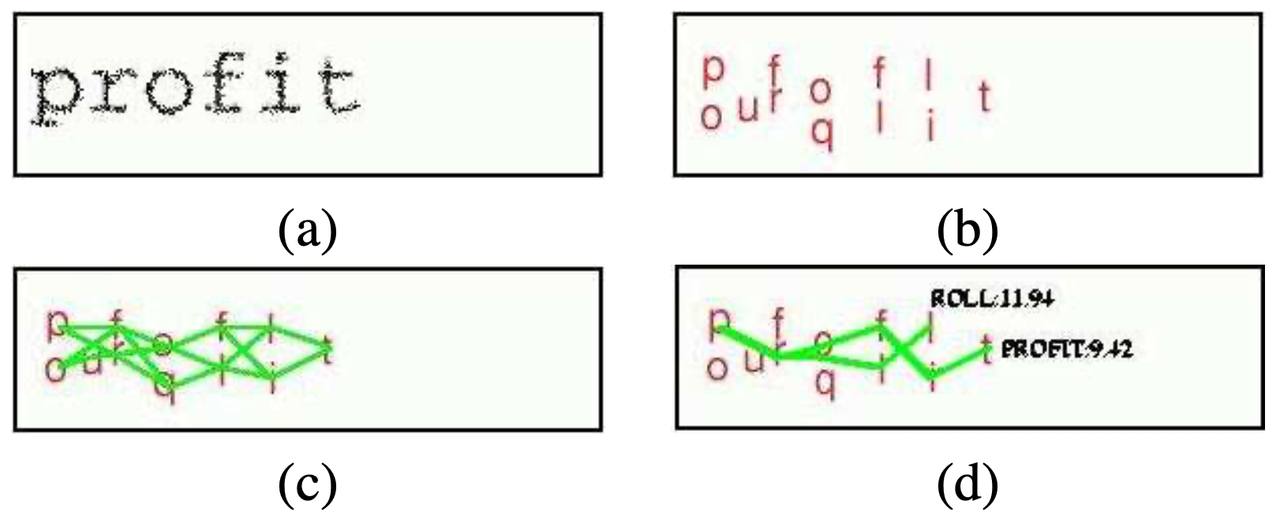
对待识别的验证码图片,先利用 Fast Pruning 进行一系列的快速检测找到图片中字母可能出现的位置以及可能的字符(按置信率从高到低排序),然后在所有可能的字符串组合(用有向无环图表示)中,找到分数最高的那个候选单词,即是对这张验证码图片的识别结果。
说到这里,关于 EZ-Gimpy 的两个重要特点必须要说明:
- EZ-Gimpy 的验证码字符串都是字典中的常见英文单词
- 一共只有 561 个单词
所以不难看出,EZ-Gimpy 实验如此高的准确率,相当一部分要归功于作者利用了该验证码的生成逻辑。但是根据 Luis von Ahn 的定义,验证码的要求之一是 Public(Greg 也在论文里提到该验证码的生成源码是公开的),而且当时 EZ-Gimpy 的确被 Yahoo 实际应用在注册账号、聊天室发言等多个场景中,所以这个实验的结果还是非常震撼的。
同样的 Gimpy 验证码也是使用的词典中的英文单词(850 个),但是 Gimpy 一张图片中有 5 组重叠在一起的扭曲单词对(但只有 7 个不同的单词),需要正确识别出至少 3 个单词并输入,才能够通过。实验依然利用“识别+字典的方式,可以达到 33%的准确率,看上去好像比第一个实验的效果差很多,但是从实际应用的角度来看,无非就是启动一个脚本变成三个脚本程序并行的区别而已,依然可以在成本较低的情况下达到接近 100% 的通过率。

结语
综上所述,可以看到几乎是从诞生之初,字符验证码就遇到了诸多强劲的对手。但是,随着各类加强版字符验证码产品的问世,再加上黑灰产在新技术应用上的相对滞后等因素,在当时,字符验证码的安全性还是可以得到一定的保证,并作为性价比极高的产品而被广泛使用。
不过,道高一尺魔高一丈,AI 和验证码的正面交锋正在人们看不到的地方悄悄酝酿着。用不了多久,随着深度学习时代的到来,以CNN 为代表的 AI 技术将迅速成为字符验证码的掘墓人。
欢迎关注下篇:「验证码与人工智能的激荡二十年:全面瓦解」
参考资料:
[1] Ahn L V , Blum M , Hopper N J , et al. CAPTCHA: Using Hard AI Problems for Security[J]. Springer, Berlin, Heidelberg, 2003.
[2] Wikipedia - Optical character recognition
[3] Lecun Y , Bottou L . Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11):2278-2324.
[4] Burges C J C , Schlkopf B . Improving the Accuracy and Speed of Support Vector Machines[C]// Advances in Neural Information Processing Systems 9, NIPS, Denver, CO, USA, December 2-5, 1996. MIT Press, 1996.
[5] Oren M , Papageorgiou C , Sinha P , et al. Pedestrian Detection Using Wavelet Templates. 2000.
[6] Belongie, Serge, Malik, et al. Shape Matching and Object Recognition Using Shape Contexts.[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2002.
[7] Medium - Shape Context descriptor and fast characters recognition
[8] Mori G , Malik J . Recognizing objects in adversarial clutter: breaking a visual CAPTCHA[C]// IEEE Computer Society Conference on Computer Vision & Pattern Recognition. IEEE, 2003.
[9] Mori G , Belongie S , Malik J . Shape Contexts Enable Efficient Retrieval of Similar Shapes[C]// Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001. IEEE, 2003.