从DGA域名识别基线模型认识网络安全任务的机器学习建模过程
从DGA域名识别基线模型认识网络安全任务的机器学习建模过程
摘要
本文面向无机器学习背景的网络安全相关工作人员,主要介绍了在网络安全问题中使用机器学习解决方案的一般分析流程。从最简单的任务DGA域名识别任务出发,介绍从数据预处理、特征构造、探索性数据分析到模型训练、评价等一系列常规建模过程。希望能帮助相关人员了解算法工程师和数据分析人员的工作方式和思考方式,以便更好地在工作中协助和互动。
一、问题描述
DGA(Domain Generation Algorithm)域名生成算法是一种常用的恶意软件工具,用于各种网络攻击,包括垃圾邮件活动、窃取个人数据和实施分布式拒绝服务(DDoS)攻击、建立C2连接等。DGA允许恶意软件在特定时间点根据恶意软件和威胁参与者共享的种子生成任意数量的域名,允许两者同步生成域名。标准技术手段如使用黑名单封禁恶意域名的方法,面对由DGA生成的大量不同域名很难进行检测,而机器学习的解决方案则提供了另外一种选择。
二、问题分析
域名(domain name),是由一串用点分隔的名字组成的Internet上某一台计算机或计算机组的名称,用于数据传输时对计算机的定位标识。有了域名,用户就不需要去记忆难记的IP,也就能方便地访问互联网。以安全狗的官网域名(www.safedog.cn)为例,域名被点号分割为三段,其中.cn是代表中国的顶级域名(Top-level domains,first-level domains(TLDs)),适用于中国国内各机构、企业。靠近顶级域名.cn左侧的Safedog是二级域名(SLD,second-level domain)。再往左的www前缀表明此域名对应着万维网服务。
DGA域名检测,从机器学习的角度看是一个区分正常域名和DGA生成的域名的二分类问题。更近一步的,域名是短字符序列类型数据。资料显示,每级域名最大长度限制是63,域名总长度限制最长是253。组成域名的字符不区分大小写,支持包括字母a-z、数字0-9、”.”点号以及”-”英文中的连字符。目前允许Unicode编码类型的字符作为域名的组成,但是我们的数据中并未出现,也是小概率事件,在我们的研究中暂时不考虑。
三、工具简介
使用的Python模块:
•Pandas: Python的数据分析库;
•Scikit learn:Python中的机器学习算法库;
•Matplotlib: Python的二维绘图库;
•statsmodels:用于描述性统计、统计检验和绘图功能;
•tldextract:用于二级域名提取;
四、研究分析步骤
Step1、数据获取
用于二分类机器学习建模任务需要标记的数据,即我们需要收集正常域名作为白样本以及DGA域名作为黑样本。在大多数DGA域名识别的研究中都使用alexa排名靠前的数据作为白样本数据,可以获取到Alexa排名前100万的域名数据,地址是:
https://aws.amazon.com/cn/alexa-top-sites/
黑样本数据一般来自研究机构公开共享的数据,DGA域名目前主要有三个来源,一是Bambenek Consulting提供的OSINT DGA feed,它包含来自50个不同DGA算法生成的DGA域名,包含80多万个恶意域名;二是DGArchive,提供了对30多个逆向工程DGA的访问,这些DGA可用生成恶意域名;三是360 netlab,提供了数十个家族DGA域名的数据。
以下是DGA域名数据的下载地址:
OSINT:http://osint.bambenekconsulting.com/feeds/
DGArchive:https://dgarchive.caad.fkie.fraunhofer.de/site/
360 netlab:https://data.netlab.360.com/dga/
本文只是介绍DGA域名基线模型的建模过程,为了更高效地运行程序,我们并不使用全部收集的数据,而是采用Alexa排名前10万的域名作为白样本,从收集的所有DGA域名中随机抽取7000+个样本做为黑样本。
Step2、数据读取与数据预处理
首先分别读取黑白样本数据,并进行常规的文本数据预处理,如去除空白符号、大小写转化等。从白样本数据开始读取:
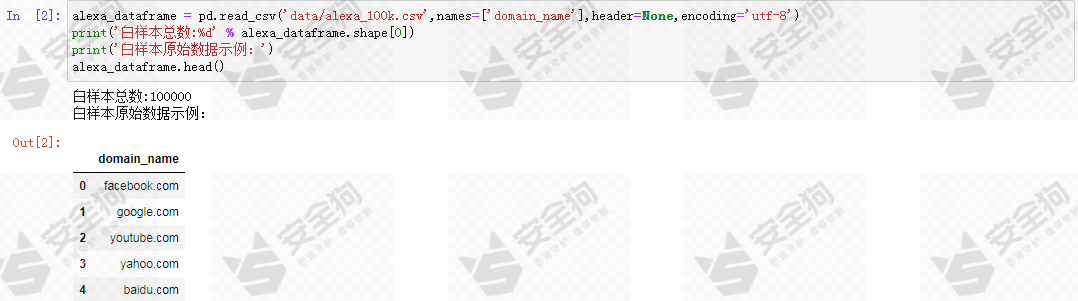
图1
为了进一步简化基线模型的研究范围,我们只关注白样本的二级域名(2LD)部分,通过 tldextract 实现二级域名提取函数 domain_extract。
 图2
图2
对白样本数据进行二级域名提取:
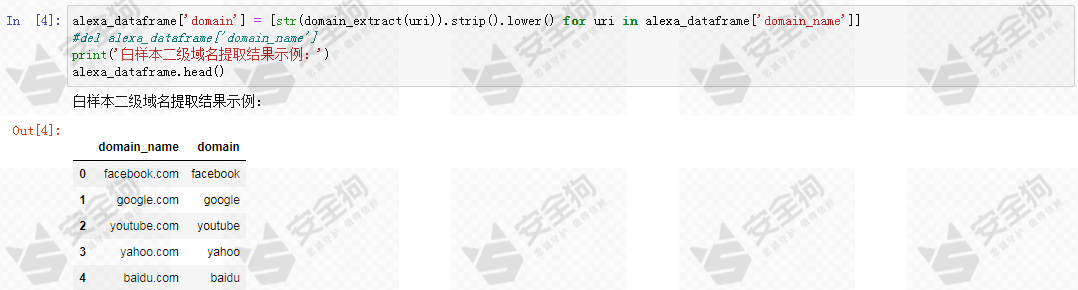
图3
接着读取和处理黑样本数据。我们的基线模型不针对DGA域名的二级域名进行分析,也不是对其完整域名进行分析,而是对其点号分割下的最左侧的域名组成片段进行分析。因为我们发现,大部分DGA生成域名的主体正是这部分。
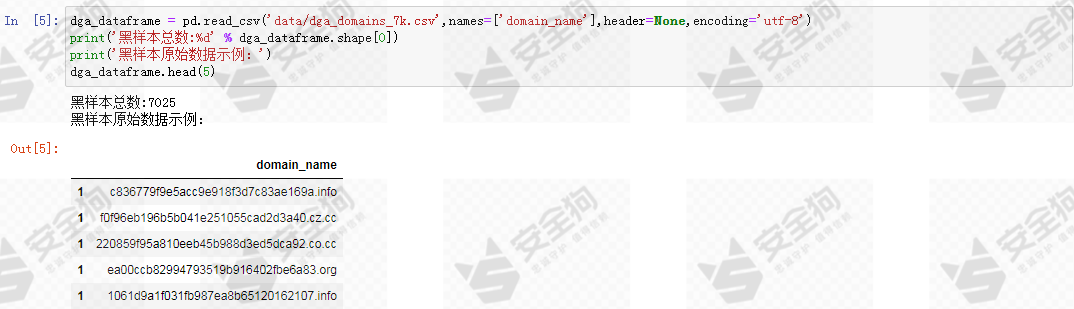
图4
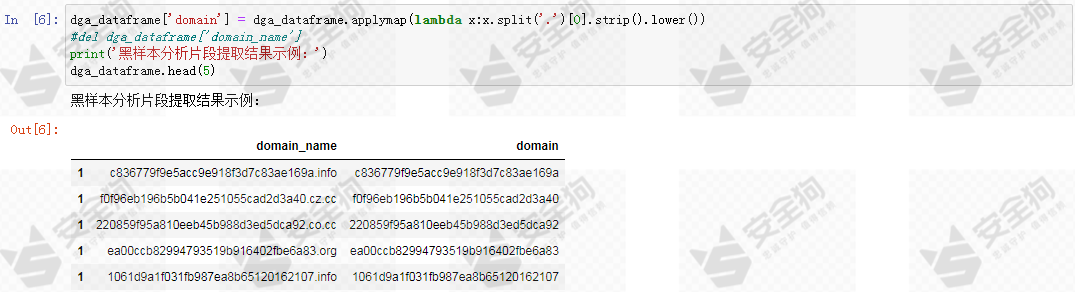
图5
Step3、数据合并和数据清洗
我们的基线模型将采用有监督的机器学习分类器,因此需要为数据打上标签。将白样本标签标记为legit,黑样本标签为dga,然后合并黑、白数据进行数据清洗。最基本的数据清洗步骤一般包括删除包含空值的行和去重等。因为我们的域名数据集非常简洁干净,所以采用基本的数据清洗方法就已足够。
数据合并和数据清洗之后,数据集的规模是 98160。
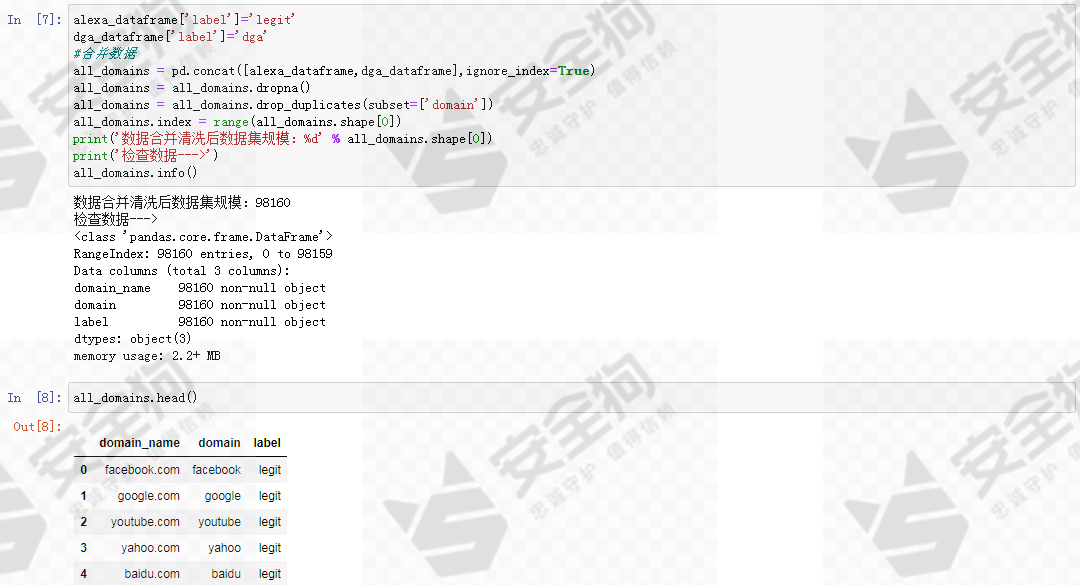
图6
Step4、特征构造和探索性数据分析
我们的基线模型采用基于人工构造特征的机器学习方案。首先需要根据领域知识,构造有意义的特征。
首先,最简单的,添加domain的字符长度(length)做为第一个特征。然而,事实上,对于很短的domain,即使是专业的网络技术人员也很难区分是DGA域名还是正常域名,况且越短的domain是正常域名的可能性越大,它们可能是企业或机构的英文缩写、拼音缩写等,当然,也有可能正是DGA域名随机生成的结果。鉴于此,我们的基线模型实验将排除domain长度小于等于6的样本。

图7
第二个特征我们选用的是字符串的香农熵。计算给定的输入字符串的香农熵H,计算方法如下:
对于给定离散随机变量X,X是由N个字符符号组成的字符串,包含n个不同的字符,则,X的香农熵为(单位bits/symbol):
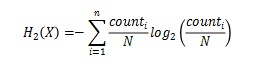
计算每个样本domain字符串的熵值,作为第二个特征值。
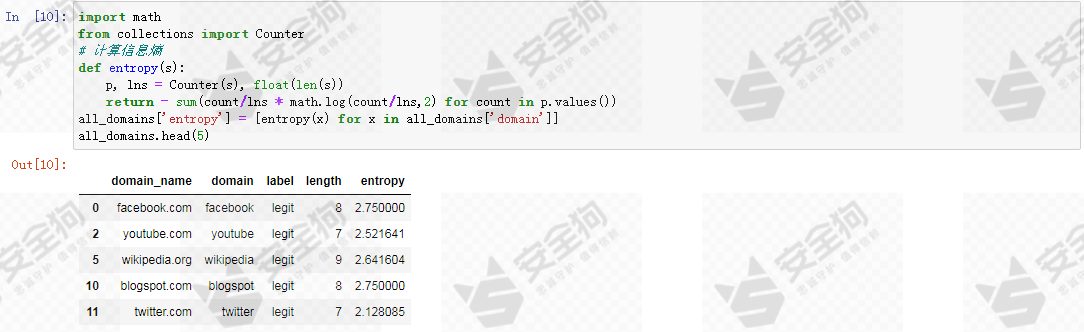 图8
图8
现在我们已经有了两个特征变量,先通过可视化方法直观看下这两个特征是否对识别DGA域名有帮助。
首先分别绘制长度特征和熵的箱型图。
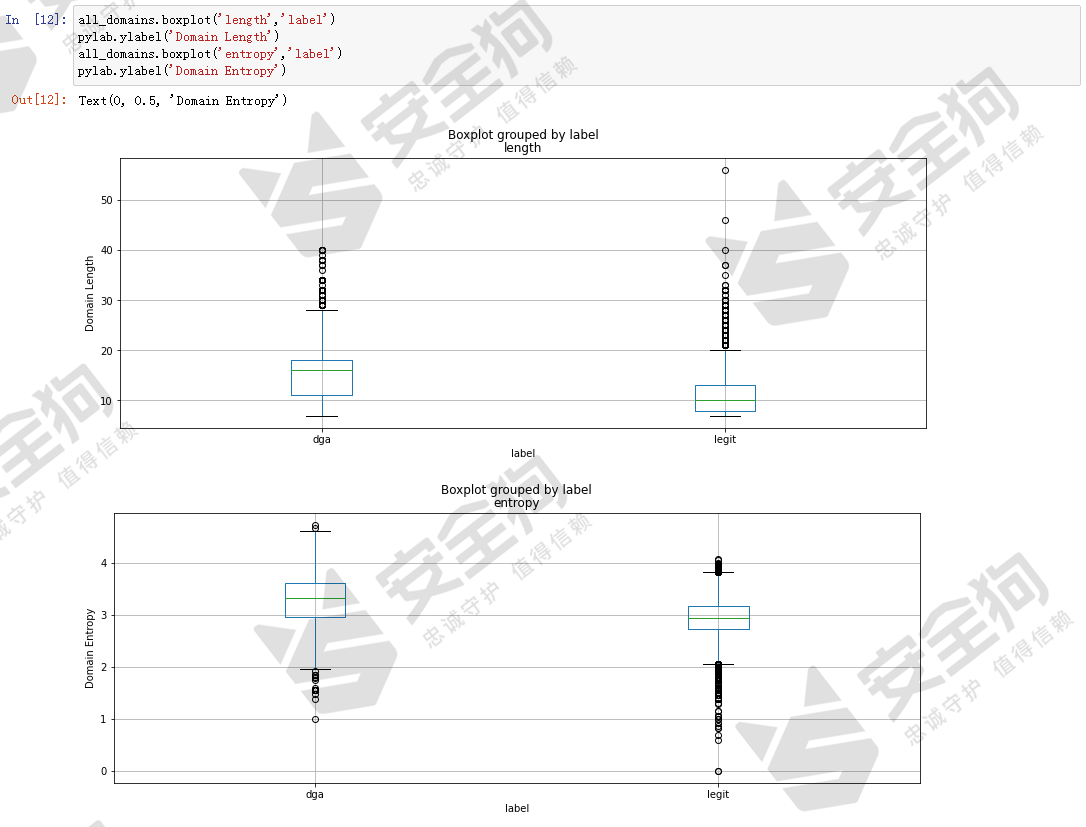 图9
图9
从箱型图可以看出,白样本域名和DGA域名的两个特征分布有一定的差异,其中DGA域名的长度特征平均值和熵特征的平均值都相对较高。
散点图的直观性比箱型图更好,我们再看看具体两个特征下的样本散点分布图。
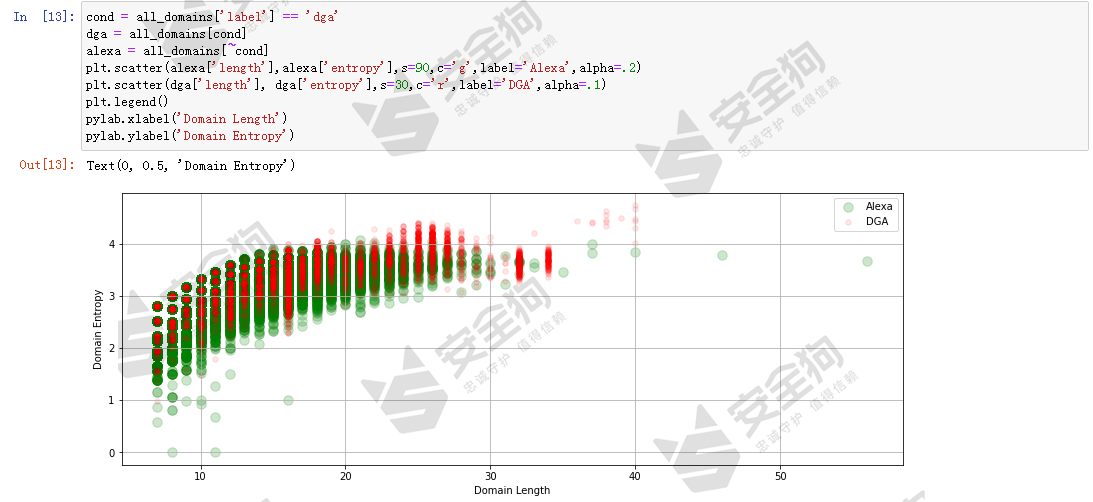 图10
图10
从特征空间散点分布图中我们可以更直观地看到DGA域名的平均熵值比白样本高。我们取熵值较大的样本出来看下样本详情,取熵大于4的样本进行分析。
 图11
图11
Step5、基线模型训练
我们将使用scikit-learn来训练模型,首先需要将我们要使用的特征取出来构造特征向量矩阵X,从label列构建目标值y。
 图12
图12
我们首先使用流行的随机森林Random Forest)模型。随机森林拟合能力强,在非神经网络模型中常常是最佳选择。使用5折的交叉验证来测试随机森林模型的表现。
 图13
图13
结果显示,随机森林的分类准确率在92.3%-92.8%左右,看起来好像效果不错,但是并非如此。试想,我们的白样本规模是67308左右,然而黑样本只有6522,类别之间的数量差距极大,是一个典型的不均衡数据集。这种情况下准确率并不是一个良好的评价指标,即使是一个很烂的模型,把所有结果都识别为白,那么准确率也能高达 67308/(67308+6522)=91.16%。
因此,我们需要更合理可靠的指标来评价模型的效果。接下来我们将数据按8:2的比例将数据集划分为训练数据和测试数据进一步对模型性能进行研究,重点关注测试数据识别结果混淆矩阵。
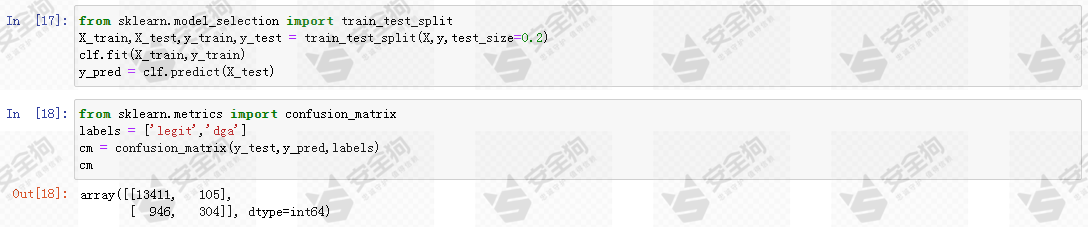 图14
图14
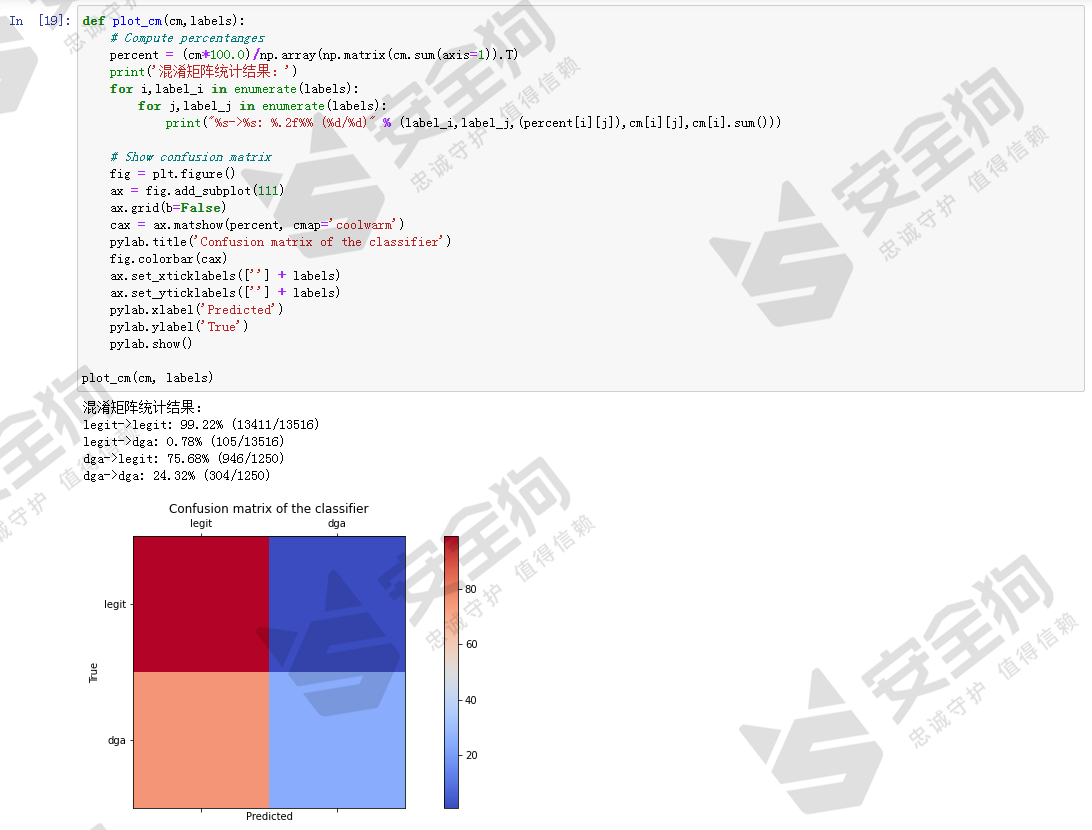 图15
图15
混淆矩阵中蕴含着大量的信息。混淆矩阵显示,在domain的长度和熵作为特征训练随机森林模型,误报很低,只有0.78%,但是召回率也很低,只有 24.32% ,也就是只能检测出 24.32% 的DGA域名。因此,目前为止的基线模型效果还很差,我们需要进一步寻找改进方法提高效果。
Step6、模型迭代优化
目前为止,我们只为基线模型设计两个特征,为了提高效果,我们首先尝试构造新的特征。首先为每个Alexa 域名的domain计算其NGram,看看是否可以使用NGrams来帮助我们更好地识别DGA域名。
sklearn的CountVectorizer支持词(word)级别和字符(chr)级别的NGram计算,对于域名而言,显然更适用字符级别的粒度。CountVectorizer的核心参数包括:ngram_range,用于指定NGram的长度范围;min_df,用于指定最小样本频率。
 图16
图16
让我们打印alexa域名中最高频的前10个NGram看看。
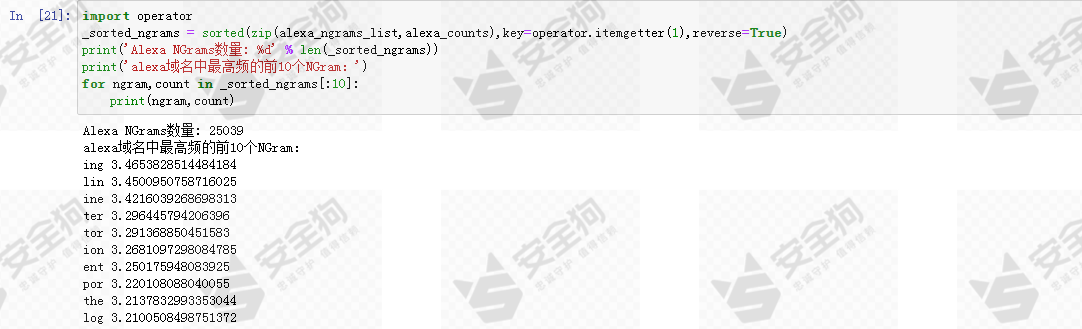 图17
图17
这些是在正常域名中最常见的NGram,也就是说,非常大比例的正常域名的组成中包含这些片段。
与此同时,我们加入一个英文词典词汇表进行同样的NGram分析。
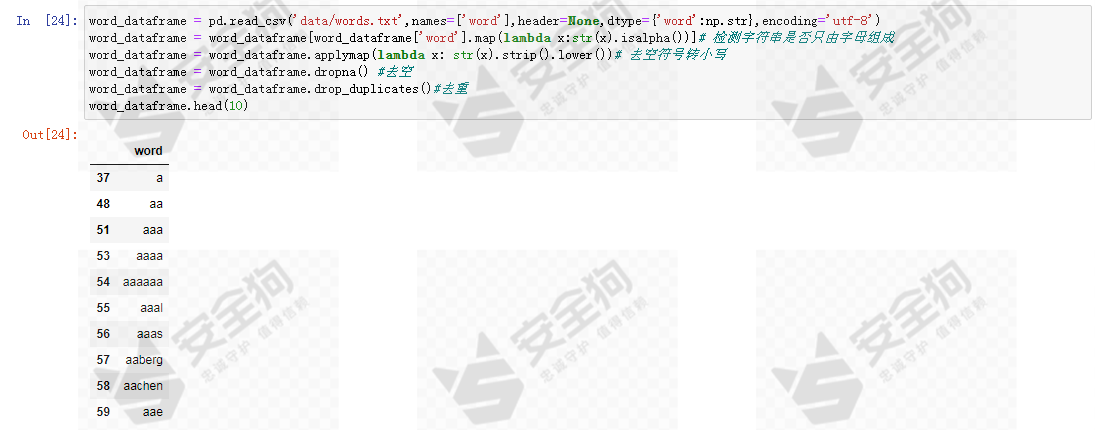 图18
图18
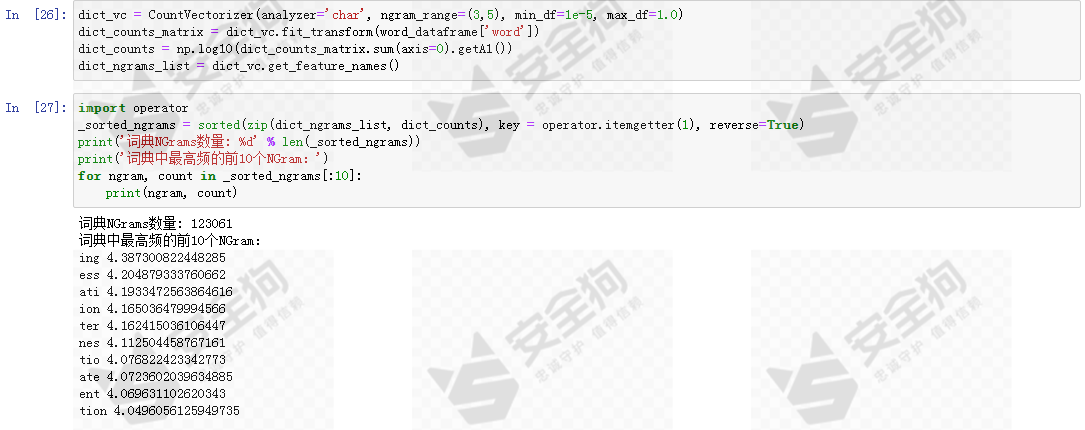 图19
图19
Alexa域名数据的高频NGram和词典数据的高频NGram有极高比例的重叠,这很符合域名注册的背景知识:域名常常被注册为有含义的好记可读性强的词汇组合,这样的域名更具有商业价值,而DGA域名是特定算法自动生成的用于恶意活动的域名,应该不会关注这些方面。
我们利用CountVectorizer的transform方法来获取域名中的ngram词频向量,该向量再乘以计数向量alexa_counts得到一个表示匹配次数的指标作alexa_grams为一个特征,同样为词典ngram设计一个word_grams特征。
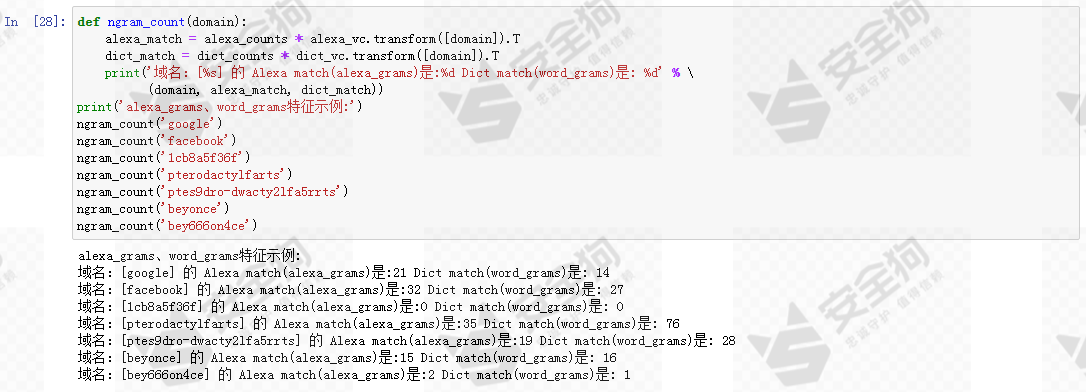 图20
图20
计算数据集中所有域名NGram的alexa_grams特征和word_grams特征,并添加到数据中。
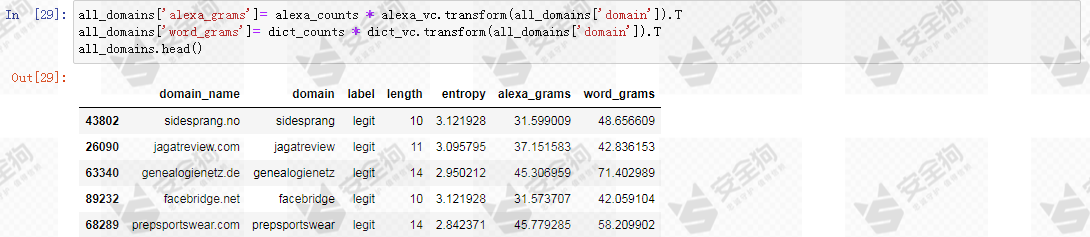 图21
图21
我们计算下alexa_grams特征和word_grams特征的差值,并对差值进行排序,以查看其效果。首先按照差值升序排序显示前20个样本,排名靠前的是word_grams更大的样本,也就是更倾向于用常见的英文词汇组成域名。我们发现其中很大比例是DGA域名,而且都是长度达到20字符以上的长域名。从网络安全的知识可知,部分家族的DGA域名是基于词典中的词汇随机组合而成的,例如:bigviktor、matsnu、ngioweb、suppobox等家族的DGA域名就是由来自预定义词典中的若干个词组合生成的,极有可能这些DGA域名正是属于这些家族。
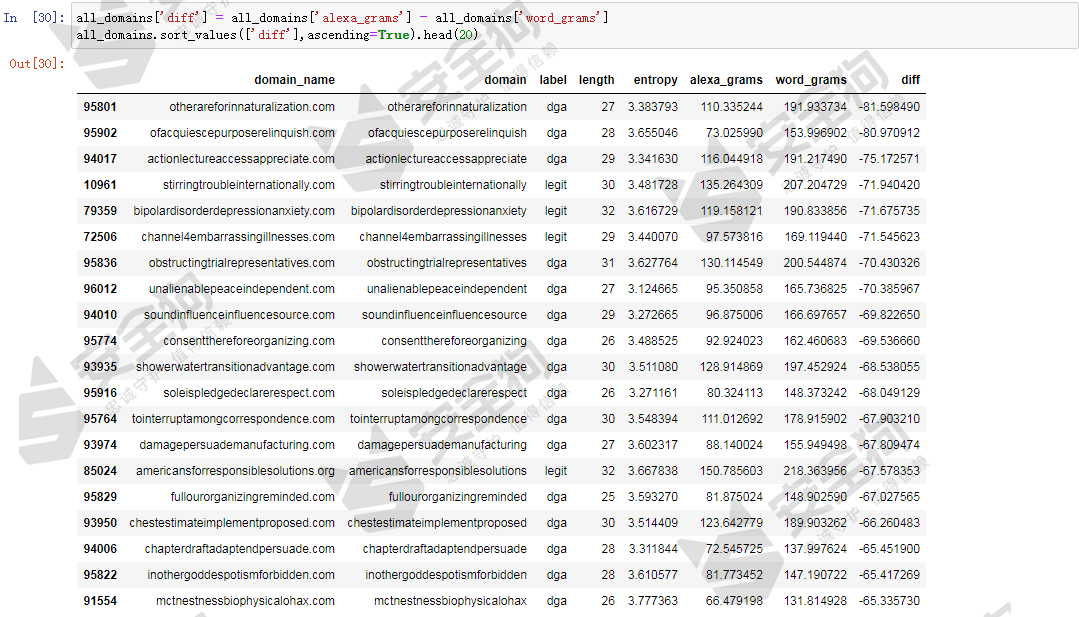 图22
图22
接着按照差值降序排序显示前20个样本,排名靠前的基板上是白样本,长度相对也比较长,基本上都是长度大于20字符。
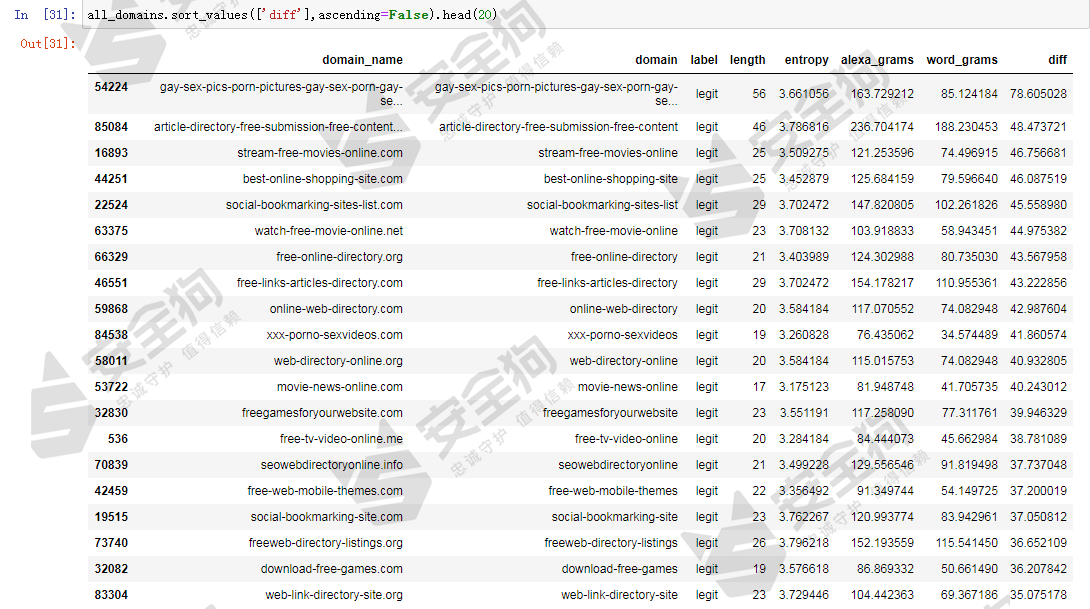 图23
图23
让我们可视化研究下,看看alexa_grams特征是否能帮助我们更好地区分正常域名和DGA域名。首先我们分别做length和alexa_grams特征空间视角下的散点图,看看黑白样本的分布情况。
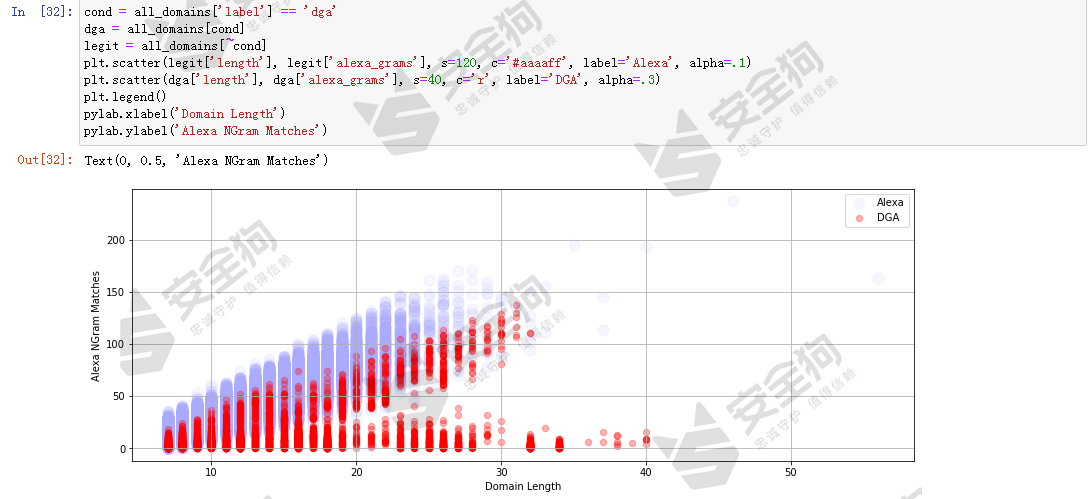 图24
图24
可以发现,长度相当的情况下,DGA域名相较于白样本域名,其alexa_grams特征值更低。这个是自然而然的,因为计算alexa_grams特征就是以alexa数据集的NGram为基础的,如果采用alexa_grams特征进行机器学习,要注意过拟合风险。另外做entropy和alexa_grams特征空间视角下的散点图,看看黑白样本的分布情况。
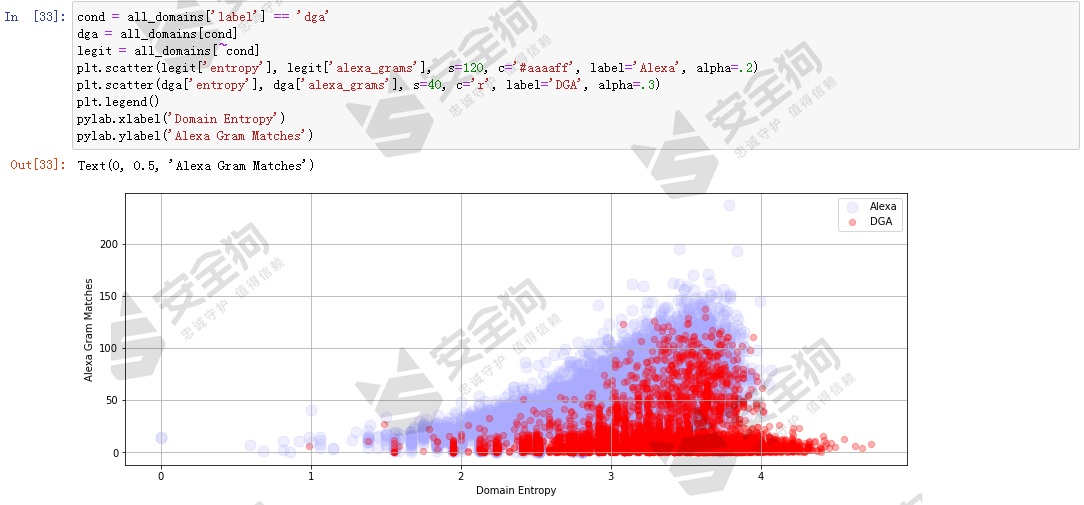 图25
图25
从散点图可以看出alexa_grams有助于区分正常域名和DGA域名。但是存在过拟合风险。
理论上word_grams特征没有过拟合风险。让我们看下word_grams特征是否也有助于区分正常域名和DGA域名,同样分别做length和word_grams特征空间的散点图以及entropy和word_grams特征空间的散点图。
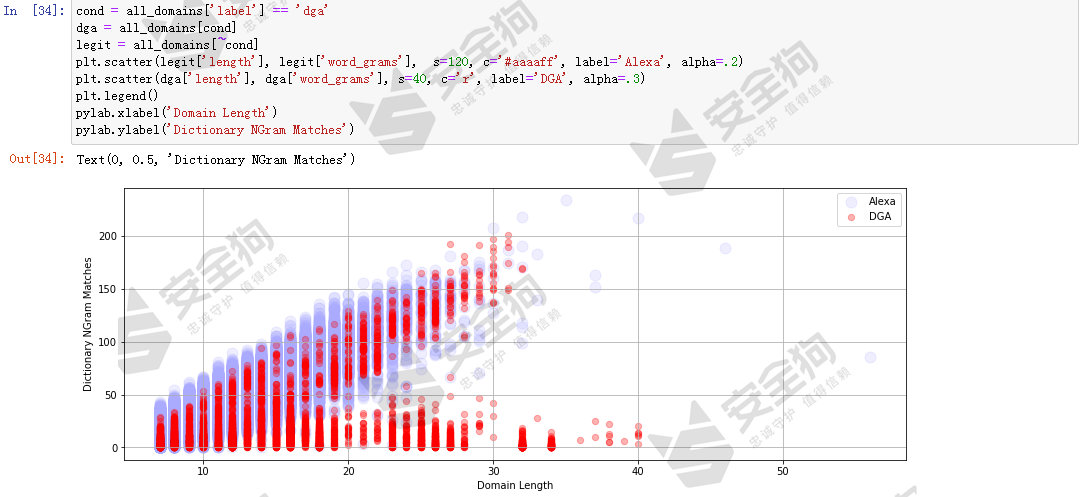 图26
图26
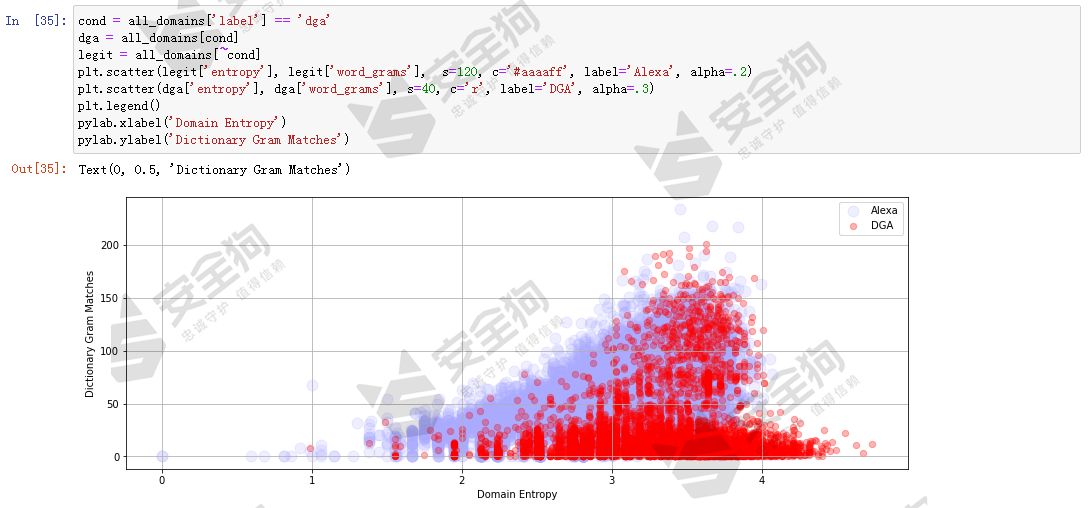 图27
图27
针对word_grams的可视化分析可以看出,分布情况从散点图可以看出,和基于alexa_grams的散点图分布情况情况大体相似。可以认为word_grams也有助于区分正常域名和DGA域名。
散点图中还显示了一些离群的白样本数据分布,其word_grams较低,把word_grams极低的白样本取出来看看是怎样的数据。
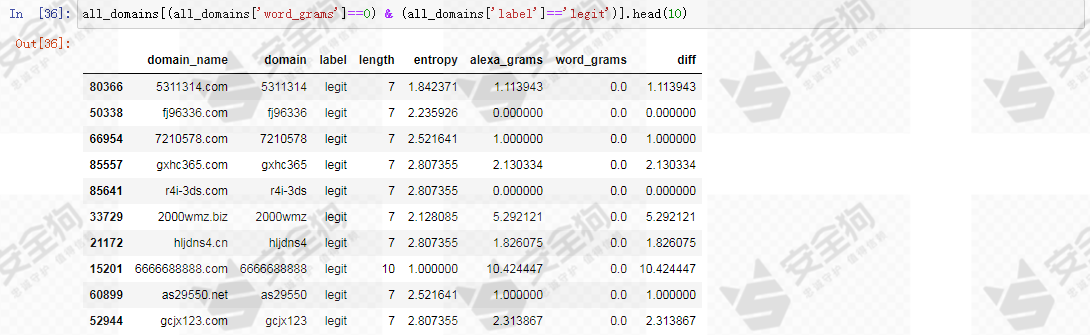 图28
图28
不难发现,这些都是可读性比较差,语义比较不明显的域名,尽管其都是白样本域名,但是让人感觉很陌生。
我们有理由反思Alexa数据集是不是恰当的DGA域名识别任务的白样本数据,它有可能存在脏数据,以及其他不合理是域名。在基线模型中,我们决定将这样的数据当成异常值处理,筛选出word_grams特征和alexa_grams特征都小于3的白样本数据标记为怪异数据,且不参与迭代模型的训练。
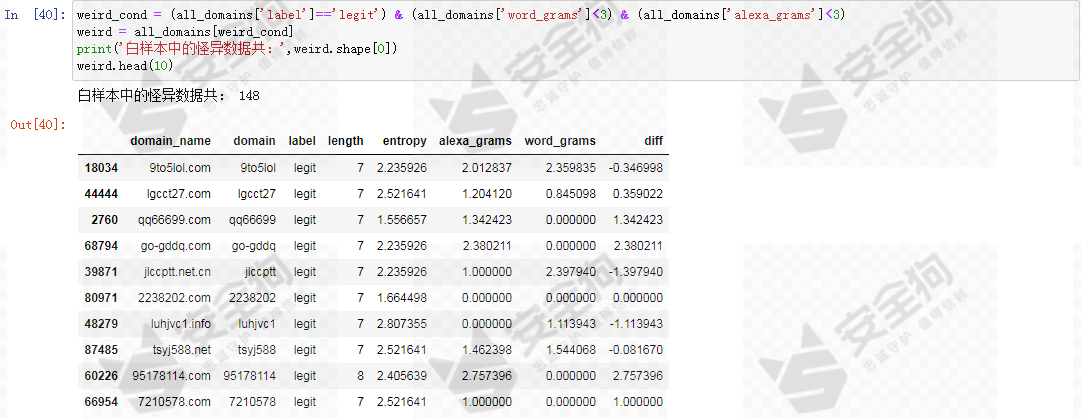 图29
图29
以上添加了alexa_grams、word_grams特征,发现了怪异的白样本数据,我们将去除怪异数据后,再次训练和评价模型,看看效果是不是有所提高。
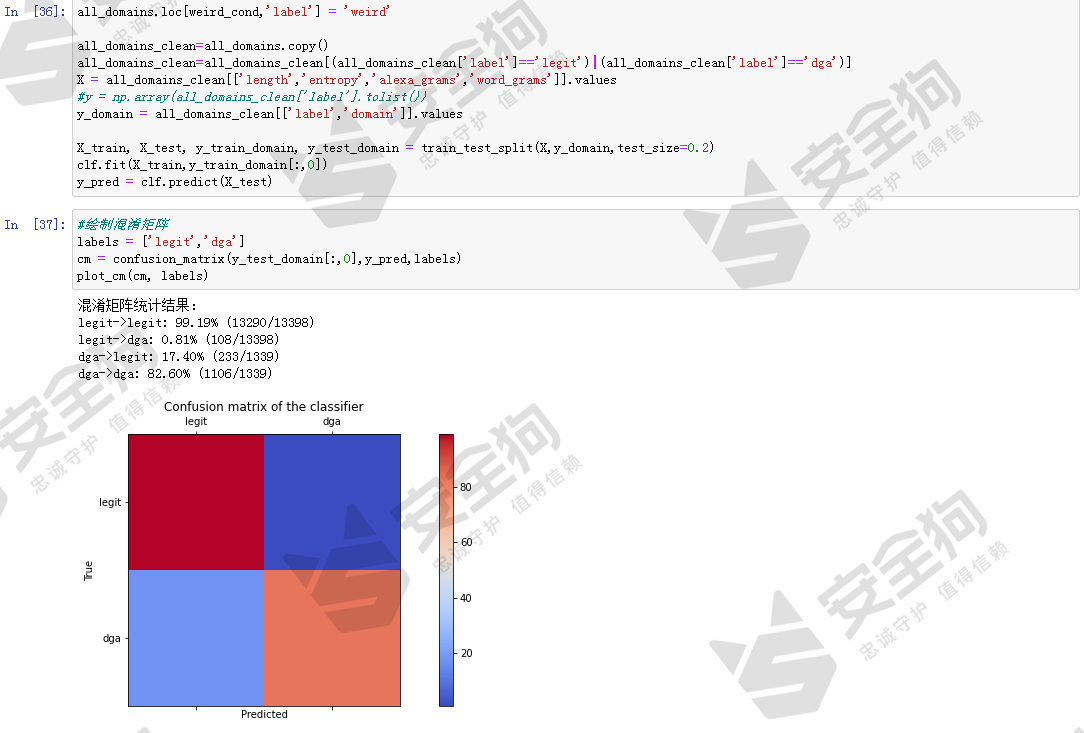 图30
图30
结果显示,在简单的改进下,模型的效果有明显提高,测试数据集中的白样本域名被识别为DGA域名的只有108条,误报率是0.81%。DGA域名的检测率从最初的24.32%提高到82.60%。仅仅添加了alexa_grams和word_grams特征,模型的效果得到了明显提高,可以说发现了黄金特征。
随机森林模型支持计算出特征对识别结果的贡献程度,也就是特征重要性指标,看下那个特征在基线模型中起了最大的作用。
 图31
图31
结果显示,alexa_grams重要性最大,而且与次重要的特征指标差距较大,一定程度上过拟合了。根据这点,我们可以进行新一轮模型迭代,删除alexa_grams特征,构造新的特征,如,元音符号占比、辅音符号占比、数字符号占比等,通过特征重要性指导特征选择,持续迭代得到更高性能更稳健的DGA域名识别模型。
五、讨论
至此,我们完成了最简单的DGA域名识别基线模型以及见识了最基本的模型迭代方法。DGA域名识别属于非常简单的机器学习任务,相关的研究也很多,基本的方法有和本文类似的采用人工构造特征,配合随机森林、支持向量机等传统机器学习模型的方案,也有采用深度学习的解决方案,常用的网络结构包括字符级LSTM、双向LSTM(bidirectional LSTM)、fasttext、textcnn等。
采用不同的简单或复杂的模型检测DGA域名的效果往往差别不大,表现非常一致,经过比较现有的研究成果,发现不同的机器学习和深度学习模型检测DGA域名的TPR指标在96.01%到99.86%之间,FPR指标在0.1%到1.95%之间,准确率指标在0.9959到0.9969之间。这也是我们为什么说DGA域名是简单任务的原因之一。
同时,DGA域名也存在难以克服的挑战,首先是基于词典生成的DGA域名对于模型来说难度很大,甚至这类域名即使是专业技术人员也很难区分,因为新的公司名新的品牌名不断出现,往往会造出新词汇,没法保证随机组合的词是否刚好就命中某个新品牌新事物。另外,目前已经出现了人工智能DGA域名生成的技术,采用的是生成对抗网络GAN(Generative Adversarial Networks),称为DeepDGA,可以生成当前机器学习、深度学习DGA域名检测模型难以识别的DGA域名。此外,必须认识到正常域名和算法生成的域名必然存在重叠部分,而且我们观察到短的(一般domain长度小于10)DGA域名以及基于词典生成的DGA域名是最容易出现与正常域名重复的情况。
在国内的汉语环境下,国内组织机构的域名除了考虑英文名、英文缩写外,还需要考虑汉语拼音及拼音缩写的域名形式,否则在英文占比高的数据集下更容易产生误报。