对抗补丁(Adversarial Patch)攻击
对抗补丁(Adversarial Patch)攻击

前言
说起AI的安全风险,除了耳熟能详的对抗样本之外,你还能想起什么攻击手段呢?本文介绍一种类似于对抗样本,但在特定方面,危害程度比对抗样本更强的攻击方案,即对抗补丁攻击(Advesarial Patch Attack),在本文的前半部分会介绍对抗补丁攻击的原理、概念,在后半部分会进行相关实验并给出两个重要结论。
概念
在对抗样本攻击中,攻击者总是希望尽可能减少扰动程度,以避免被发现,但是在对抗补丁攻击中,攻击者不再将自己限制在难以察觉的变化中。该攻击方案会生成一个与图像无关的补丁,然后可以将此补丁放置在图像中的任何位置,如此便能攻击分类器,让其输出指定的目标类别。如下是一个真实的例子
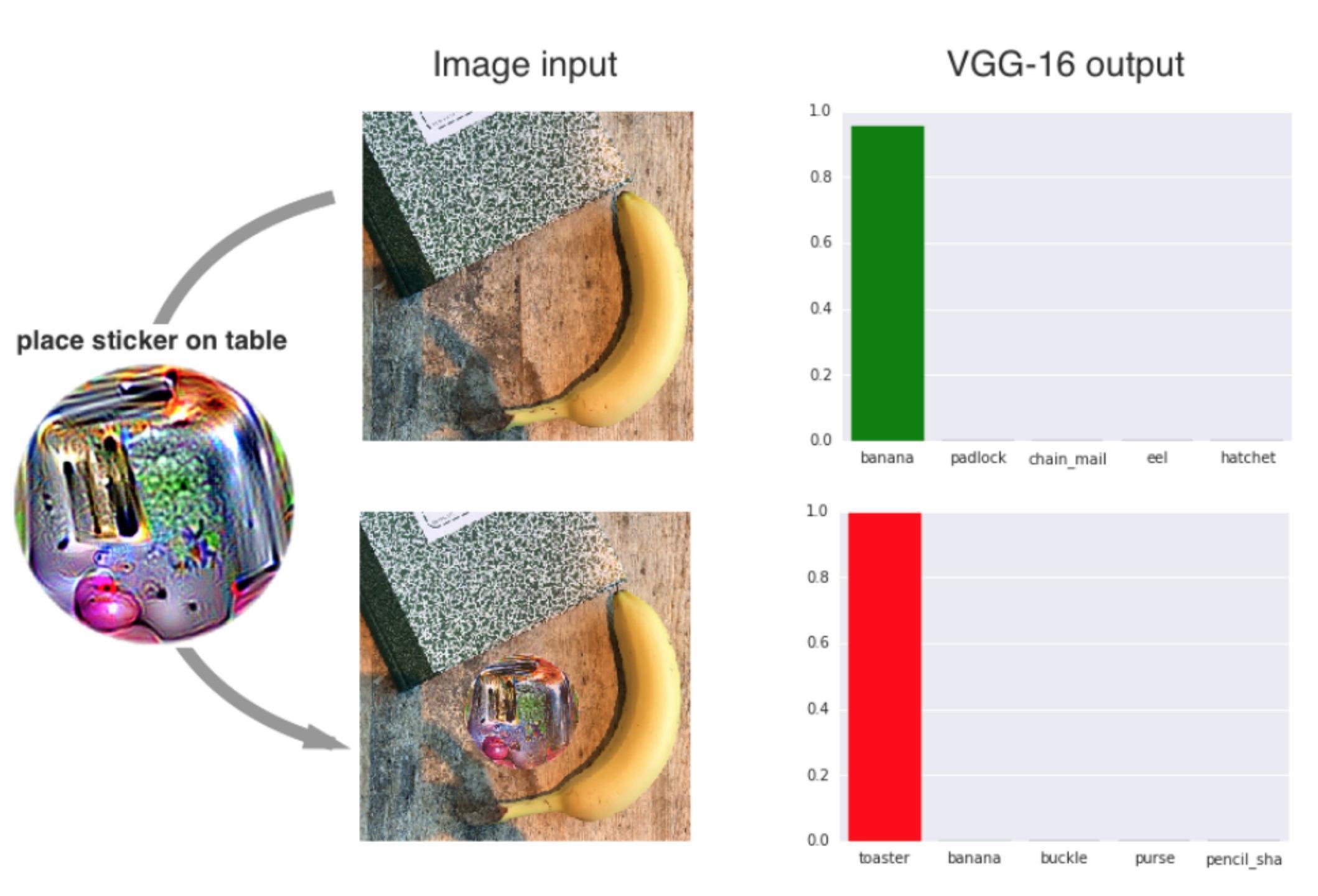
这是对线下实际部署的vgg16模型的攻击,上方是正确识别了香蕉,但是当补丁被加到图像中后,模型就会将其分类为烤面包机。这种攻击的好处在于,攻击者不需要知道被攻击的图像是什么样的,只需要将补丁加上,模型就会被欺骗,误分类到补丁对应的类别去,所以从攻击危害而言,远大于对抗样本。
辨析
现在我们知道的攻击手段有对抗样本攻击、对抗补丁攻击、后门攻击,他们之间有什么区别呢?
从添加的扰动层面来看,就通用性而言,对抗样本需要的扰动是特定于原样本的,而对抗补丁攻击、后门攻击所用的扰动是一次性生成,之后不论任何样本,一旦将扰动添加上去,样本就会被误分类;就扰动模式而言,对抗样本攻击、对抗补丁攻击的扰动模式是特定的像素,由算法自动生成,而后门攻击的扰动模式可以由攻击者指定,可以是有意义的图像等;就可见性而言,对抗样本攻击的本质就需要确保扰动足够小,以至于人眼无法区分,而后门攻击在近年来来实现了隐蔽的扰动,但是对抗补丁攻击由于要确保模型会将对抗补丁模式作为分类的特征,所以必须确保补丁相比于原样本而言要有足够的区分度,或者说要更加容易被模型学习,所以其可见性是最高的。
可见,任何攻击手段都有其局限性,在各方面都有所取舍。对抗攻击在攻击时最隐蔽,但是每次攻击都需要生特定扰动;对抗补丁攻击最不隐蔽,但是不需要修改模型,一旦生成扰动,将其叠加于原样本上即可实现攻击;后门攻击隐蔽性居中,生成扰动(在后门攻击中对应术语为触发器)后,将其叠加与原样本即可实现攻击,但是需要修改模型。
原理
前面已经说过,我们通过用补丁来替换原图像的一部分实现攻击。为了保证补丁的鲁棒性,我们对补丁应用随机的平移、缩放、旋转,并使用梯度下降进行优化。
对于给定图像x,补丁p,补丁位置l,以及补丁变换t(包括旋转、缩放),我们可以定义补丁应用操作符(patch application operator)A(p,x,l,t),它首先将t应用到p上,然后将经过变换的补丁p放到图像x的位置l上,如下图所示

攻击者训练补丁以优化目标类别的预期概率。为了得到补丁,我们可以使用EoT[3]的变种技术,通过优化下面的公式就可以得到补丁。
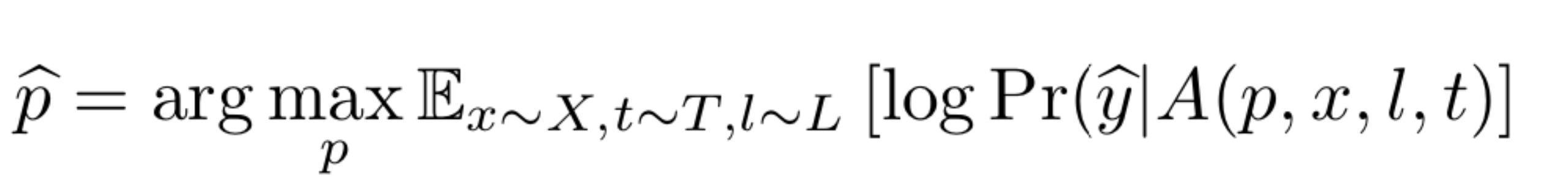
其中,X是图像的训练集,T是补丁变换的分布,L 是图像中位置的分布。注意,这里的期望是针对图像的,这可以保证生成的补丁无论在什么背景下都是有效的。
这种攻击方案利用的是图像分类任务内部的决策方式。虽然一张图像可能有多个item,但是由于图像对应的标签只能有1个,所以模型必须学会检测出图像中最显著的item。而对抗补丁的目的就是通过产生比一般图像原来的item更显著的输入来导致模型根据对抗补丁做出分类结果,从而实现攻击。
其实整个实施过程和FGSM等对抗样本有点类似。本质上都是计算对于输入的梯度,然后相应地更新我们的对抗输入。但是有一定差别。首先,我们不是为每个像素计算梯度,相反地,我们先用补丁替换原图像的对应区域,然后只对补丁区域计算梯度。其次,我们并不是只为单个图像计算梯度,因为我们的攻击目标是任何图片加上我们的补丁都能欺骗模型。
实战
加载模型
我们使用预训练好的Resnet34,加载该模型

在攻击开始之前,我们先来看看模型的性能。注意一下,由于ImageNet有1000个类,仅看准确率并不足以判断模型的性能。如果有一个模型,它总是将真实标签预测为softmax输出中第二高的类别,尽管它识别了图像中的对象,但它的准确率为 0。在具有1000个类的ImageNet中,并不总是有一个明确的标签可以为图像分配。 所以我们经常会用一个常见的替代指标,即Top-5 accuracy,它告诉我们真实标签在模型的5个最可能的预测中出现了多少次。由于模型通常在这些方面表现良好,我们检测模型的error而不是accuracy:
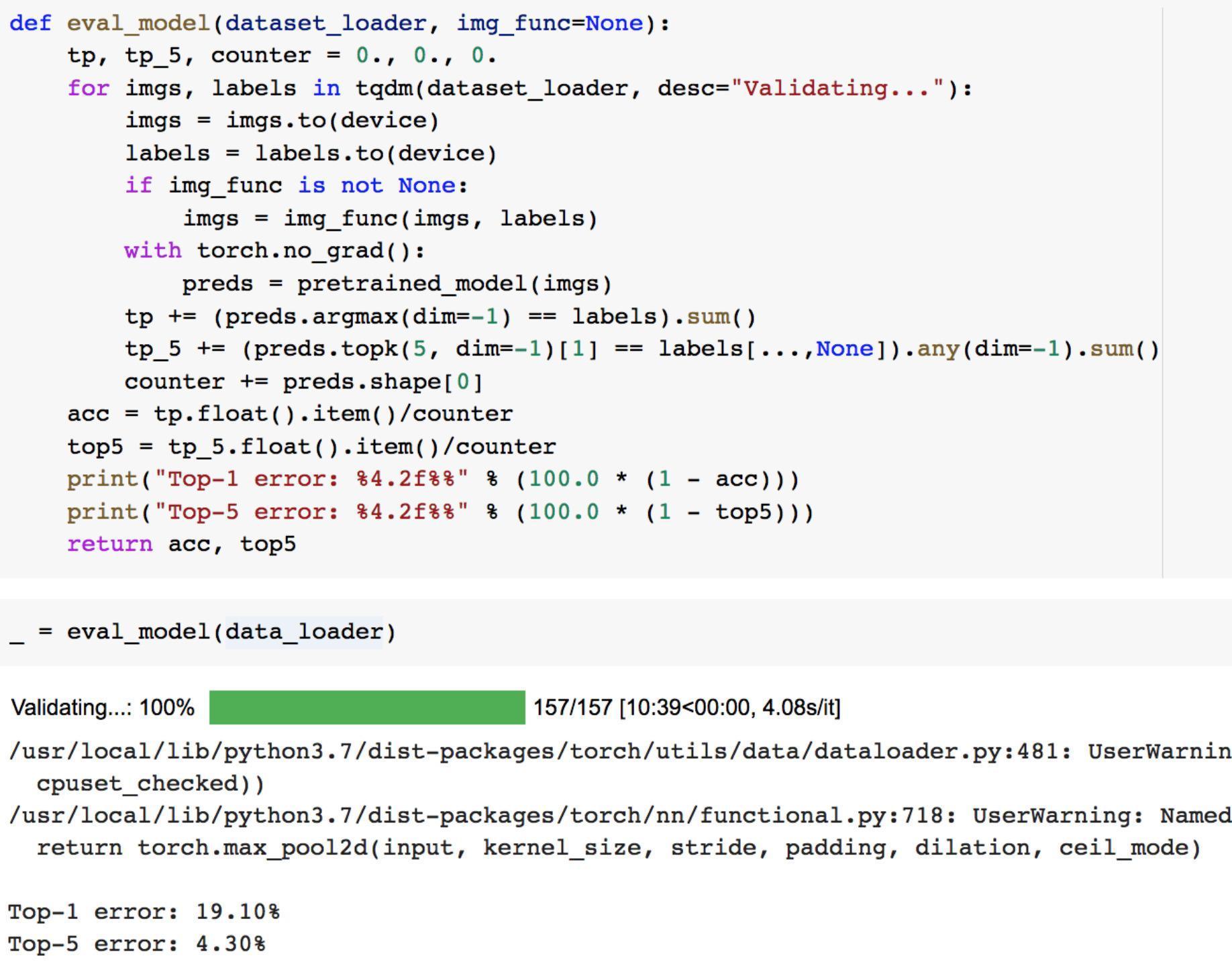
Top-5的error已经比较低了,说明这个模型性能不错。我们可以进一步打印出测试图片,以及模型对其预测结果
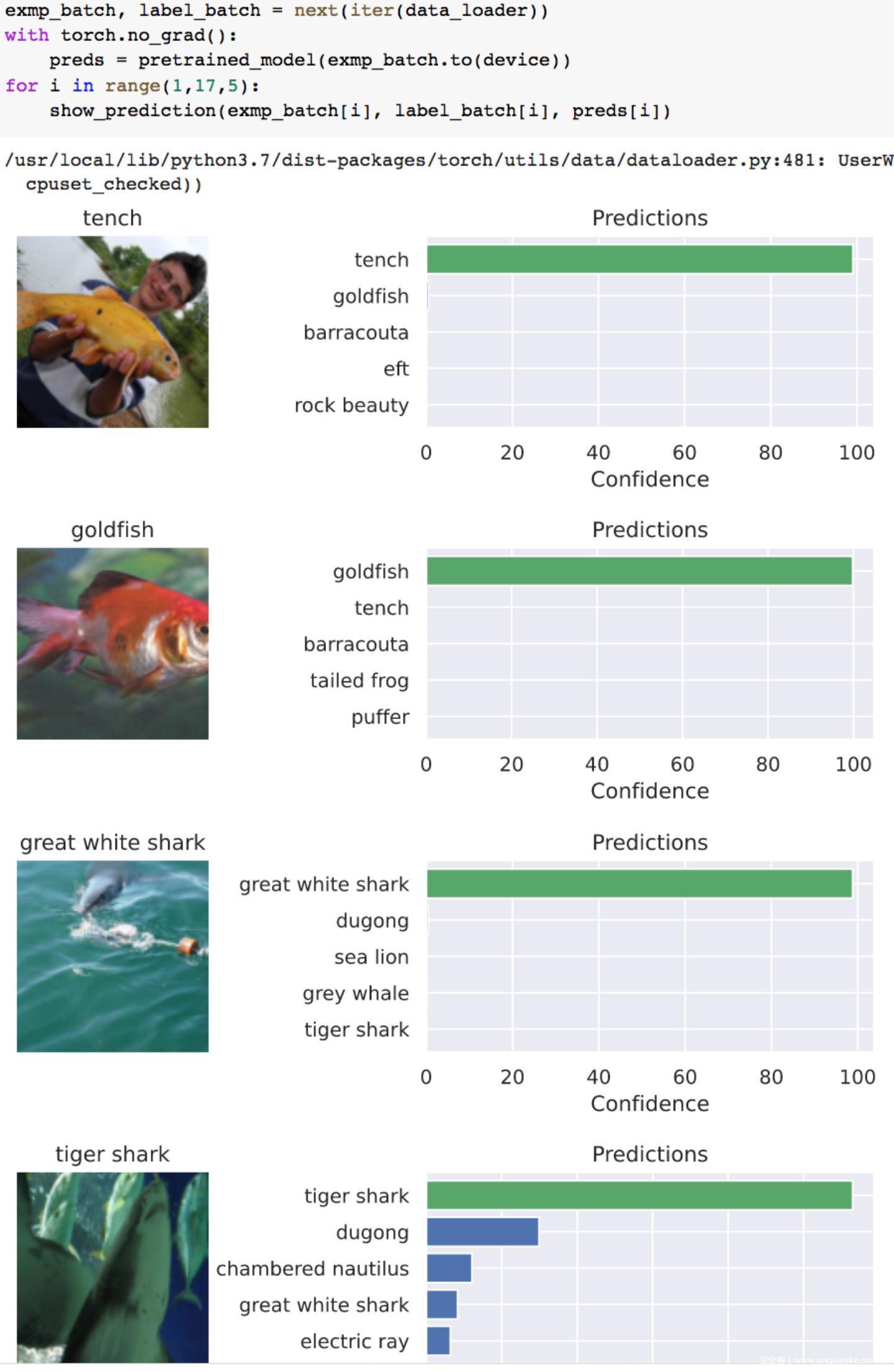
上图中左边图像是测试数据,上方是其真实标签,右边是对应的预测结果。右侧的条形图显示了模型的前5个预测及其类别概率。我们用confidence置信度表示类别概率.
从预测结果来看,都是分类正确的
接下来我们开始看看攻击部分的代码
由于要加的补丁是nn.Parameter,它的取值范围是负无穷到正无穷,而图像取值范围是有限的,所以需要将其映射到ImageNet的图像值范围

在给定图像和补丁后,为了确保补丁对位置的鲁棒性(即不论补丁加到图像的哪个位置都可以攻击成功),我们可以按照下面的方式添加补丁,即在图像内随机选择偏移量

接下来实现评估函数,用能够欺骗网络预测攻击者指定的目标类别的次数来评估补丁的成功率

然后我们来实现制作补丁的函数,输入是要攻击的模型,目标类别,以及补丁的规模k,我们首先创建一个大小为 3×kxk的参数。给定带补丁的图像,我们使用SGD优化器来最小化模型的分类损失。一开始训练时,损失是非常高的,但一旦我们开始更改补丁,损失就会迅速下降。最后,补丁将代表目标类的特征模式。例如,如果我们希望模型将每张图像预测为金鱼类别,那么我们希望该模式看起来像金鱼。在迭代过程中,模型会微调模式,并有望实现高欺骗精度。
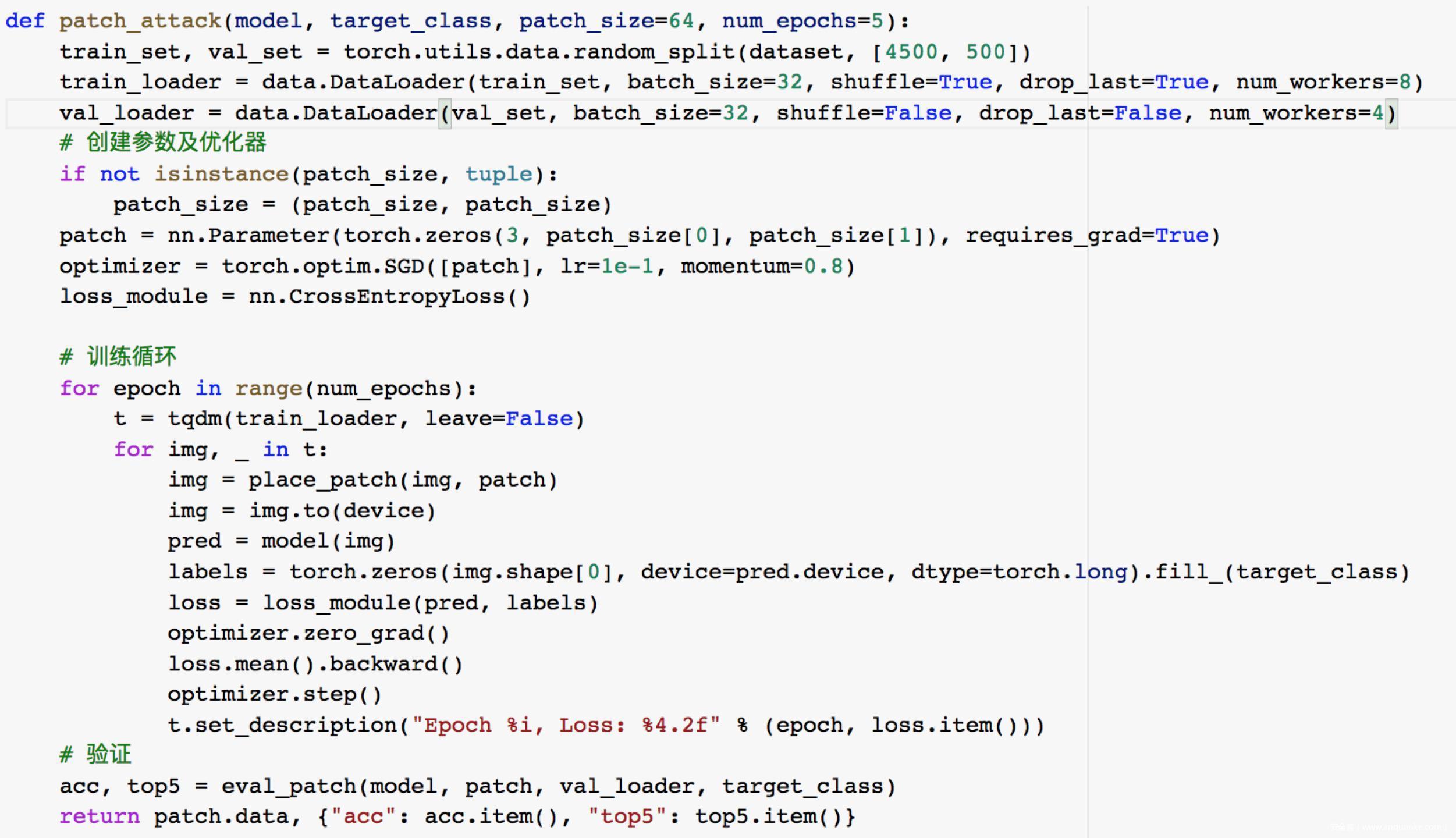
下面攻击时补丁可选的参数,即补丁类型和补丁规模

生成补丁后,为了更直观体验到不同类型和规模的差异,我们可以将其可视化
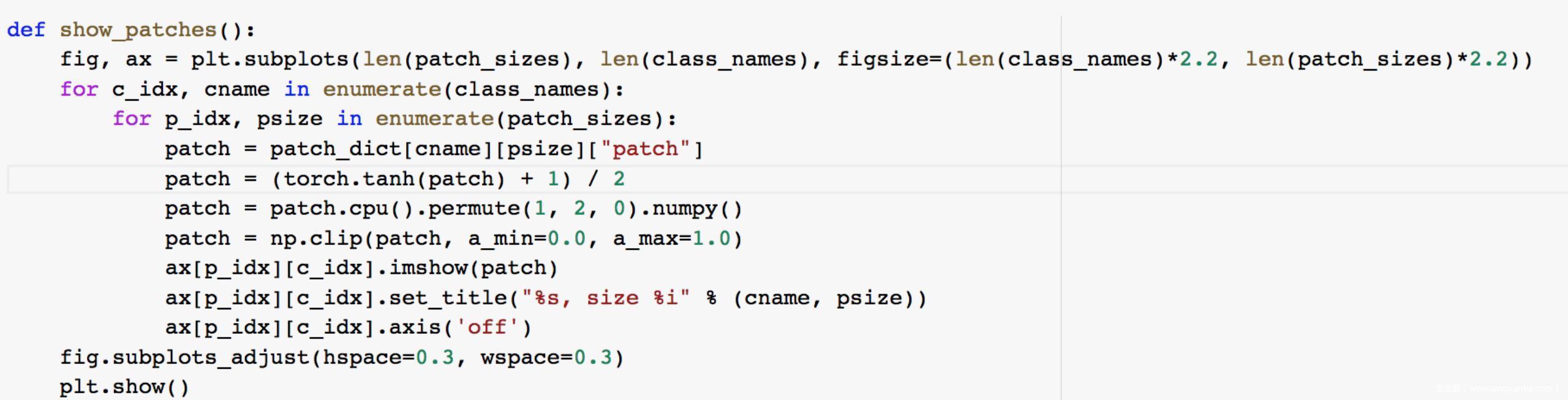
结果如下

可以看到不同类别和规模的补丁差异很明显。在最小规模(32×32)中,一些补丁与它们的标签明显符合。比如金鱼补丁清楚地显示了一条金鱼,从它的眼睛和颜色都能看出来。总体而言,32*32的补丁具有非常强烈的颜色,这是它们所对应标签的典型颜色(黄色的校车、粉色的唇膏、绿色的菠萝等)。而随着补丁规模变大,图像就被拉伸了。比如对于金鱼补丁而言,仍然可以看到可能代表眼睛和颜色特征的区域,但它显然不再是一条鱼了。大规模的补丁比小规模的补丁更抽象。
我们看看模型对他们的预测是怎样的

从结果可以看出,虽然规模越大的补丁在人眼看来越抽象,但是被分类的正确率反而是越高的
对抗补丁攻击
接下来我们开始正式进行攻击,以下是执行对抗补丁攻击的函数

我们在原图上打上金鱼补丁,也就是在每张测试图片上叠加上金鱼的图片

我们将打了补丁的图片交给模型来进行分类,结果如下。下图中每张图片的上方是正确的标签,比如第一张图片正确的标签是鲤鱼
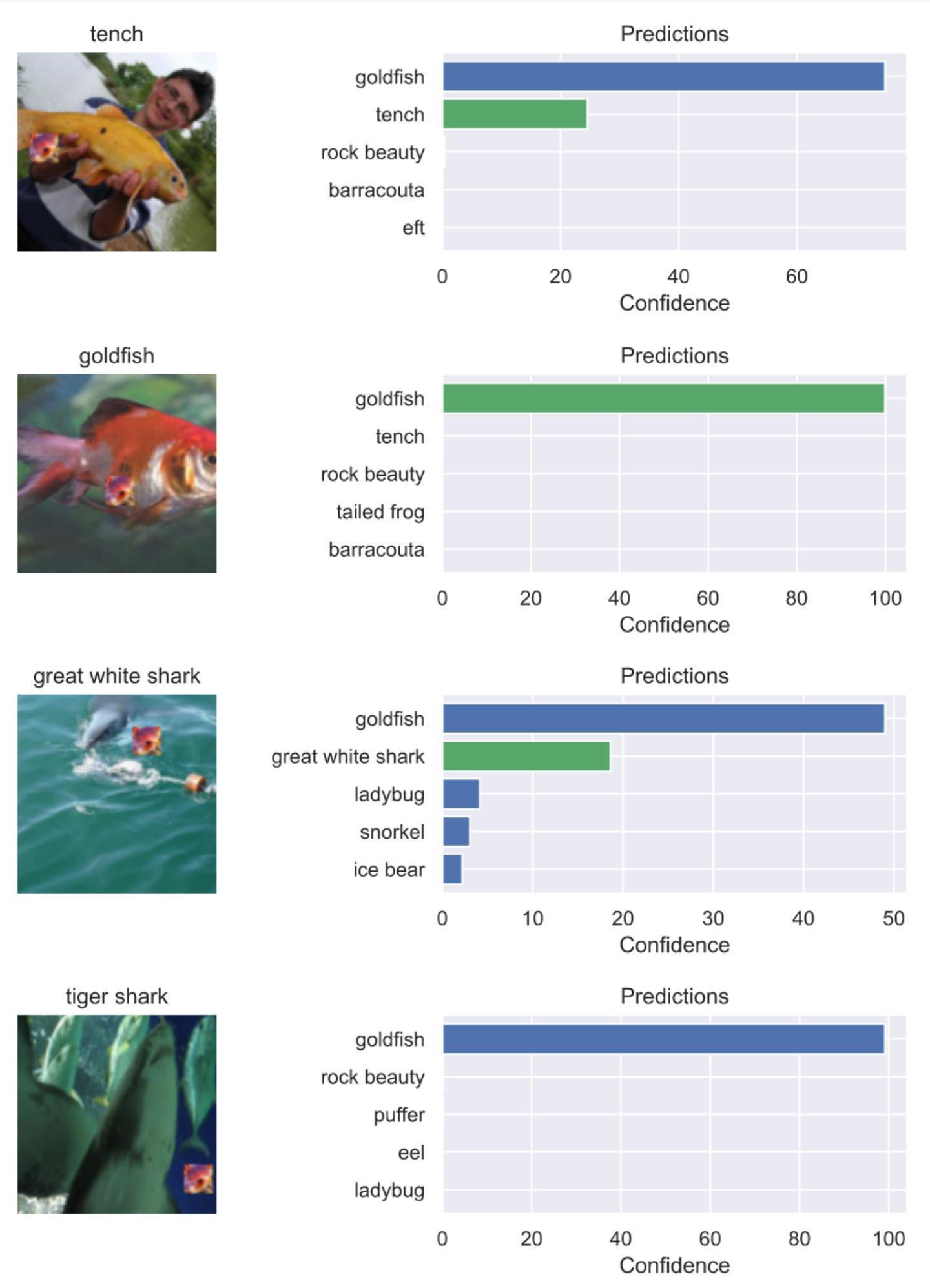
上图有右侧的图片是模型给出的对左边对应图像的预测,可以看到打了金鱼补丁的图片,斗是以最高的置信度被分类为了金鱼。说明我们的攻击成功了。
不过我们注意到第一张鲤鱼和第三张白鲸的图片,预测为金鱼的置信度并不是100%,还有20%左右的置信度将其预测为原来的标签。
那么为了使攻击更彻底一些,我们可以加大补丁的规模,将其从32改为64,攻击结果如下
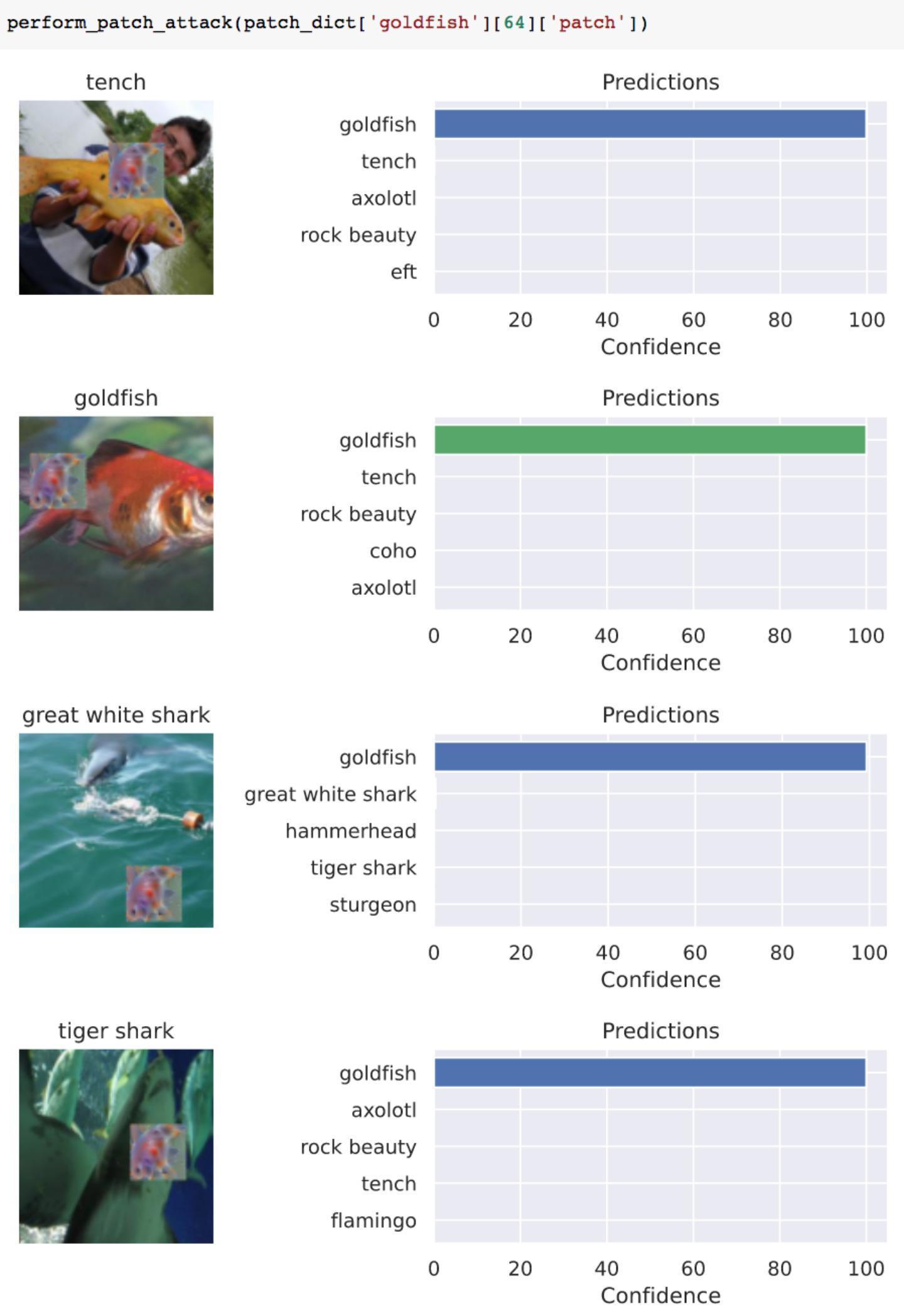
可以看到此时四张图片均以100%的置信度分类为虎鲸了。
当然,这个实验可能说服力不是很强,毕竟原来的图片其正确标签就是鱼,比如上图分别是鲤鱼、金鱼、白鲸、虎鲸,这时候打的补丁又是鱼,分类之后的结果是鱼,可能仅仅是模型训练得不够好?为了否定这种猜测,我们可以进一步做一个差别比较大的实验。
我们还是对于这四张鱼类的图片进行实验,但是打的补丁是校车,攻击结果如下
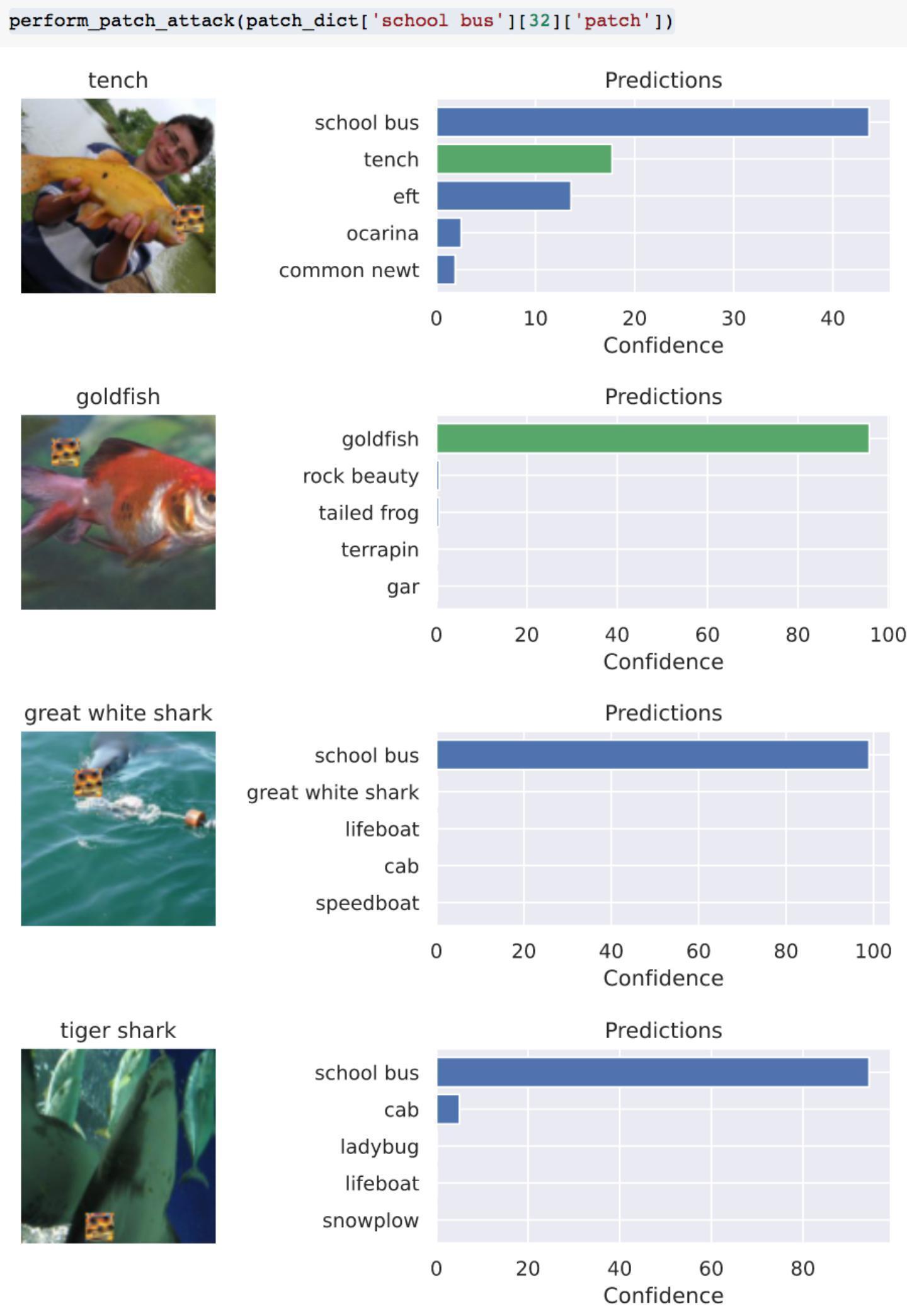
从结果可以看出,第1张和第4张的预测结果分类为校车的置信度并不是100%,同时此时攻击对于第二张图片是失效的,模型依旧将其预测为金鱼。
那么我们可以加强攻击力度,同样将调大补丁的规模,攻击结果如下
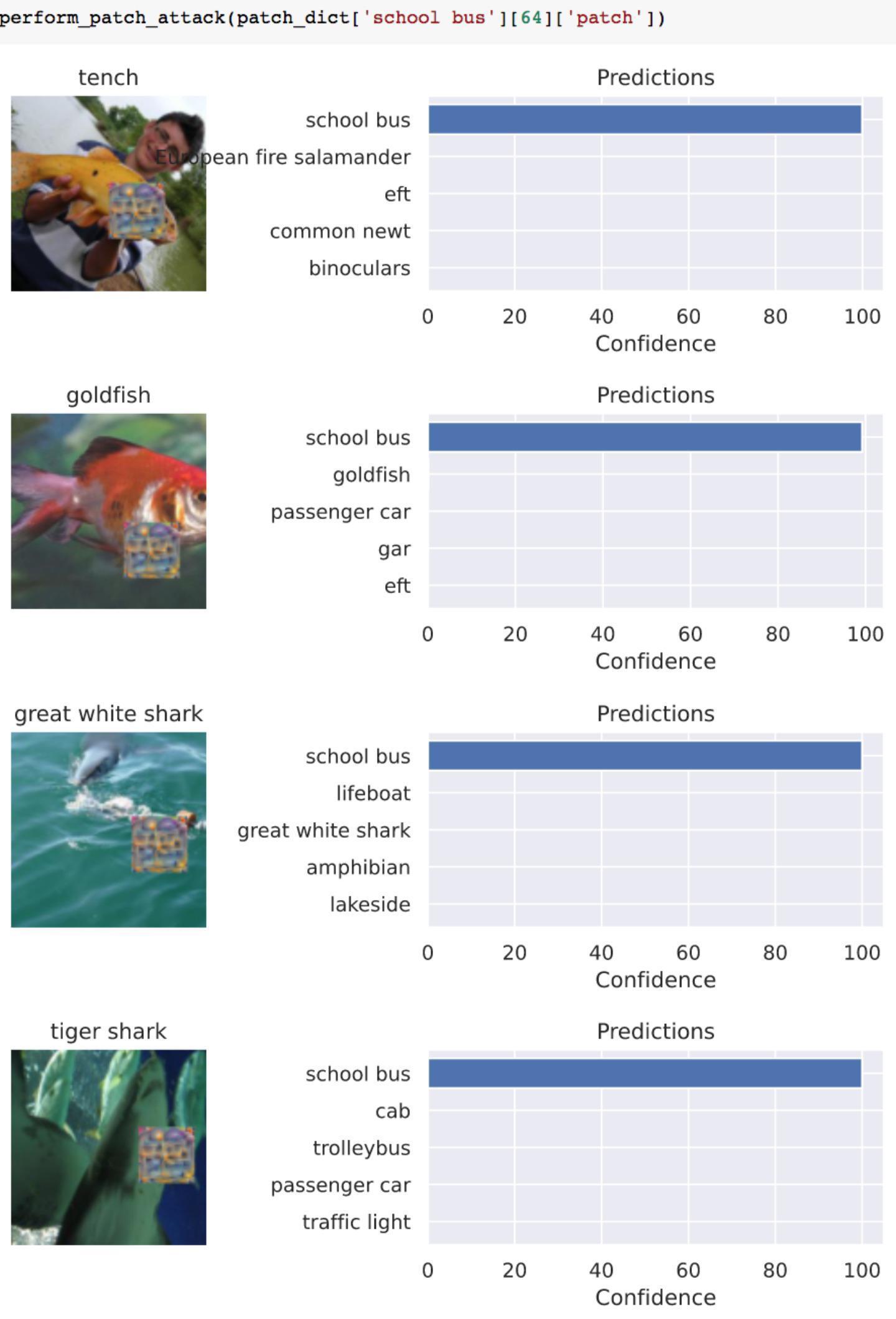
此时模型以100%的置信度将四张图像误分类为了校车,说明攻击成功了。
总结一下,这一系列实验告诉了我们两个结论:1.当我们要攻击的图像与希望模型做出误分类的类别在语义上是相关的时候,攻击更容易成功(在我们的实验里可以看到,在鱼类图像上打金鱼补丁的攻击比在鱼类图像上打校车的补丁攻击更容易成功);2.增加补丁的规模可以使得攻击效果更好。
参考
1.Brown T B , D Mané, Roy A , et al. Adversarial Patch[J]. 2017.
2.https://www.youtube.com/watch?v=i1sp4X57TL4&feature=youtu.be
3.Athalye A , Engstrom L , Ilyas A , et al. Synthesizing Robust Adversarial Examples[J]. 2017.
4.https://github.com/jhayes14/adversarial-patch
5.https://github.com/A-LinCui/Adversarial_Patch_Attack
6.https://github.com/sukrutrao/Adversarial-Patch-Training