Python人工智能 | 十六.Keras环境搭建、入门基础及回归神经网络案例
Python人工智能 | 十六.Keras环境搭建、入门基础及回归神经网络案例
从本专栏开始,作者正式研究Python深度学习、神经网络及人工智能相关知识。前一篇文章详细讲解了无监督学习Autoencoder的原理知识,然后用MNIST手写数字案例进行对比实验及聚类分析。这篇文章将开启Keras人工智能的学习,主要分享Keras环境搭建、入门基础及回归神经网络案例。基础性文章,希望对您有所帮助!
本专栏主要结合作者之前的博客、AI经验、“莫烦”老师的视频学习心得和相关文章及论文介绍,后面随着深入会讲解更多的Python人工智能案例及应用。基础性文章,希望对您有所帮助,如果文章中存在错误或不足之处,还请海涵~作者作为人工智能的菜鸟,希望大家能与我在这一笔一划的博客中成长起来,该专栏作者会用心撰写,望对得起读者,共勉!
文章目录:
- 一.为什么要使用Keras
- 二.安装Keras和兼容Backend
- 1.如何安装Keras
- 2.兼容Backend
- 三.白话神经网络
- 四.Keras搭建回归神经网络
- 五.总结
代码下载地址(欢迎大家关注点赞):
- https://github.com/eastmountyxz/
- AI-for-TensorFlow
- https://github.com/eastmountyxz/
- AI-for-Keras
学Python近八年,认识了很多大佬和朋友,感恩。作者的本意是帮助更多初学者入门,因此在github开源了所有代码,也在公众号同步更新。深知自己很菜,得拼命努力前行,编程也没有什么捷径,干就对了。希望未来能更透彻学习和撰写文章,也能在读博几年里学会真正的独立科研。同时非常感谢参考文献中的大佬们的文章和分享。
- https://blog.csdn.net/eastmount
一.为什么要使用Keras
Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化 。其主要开发者是谷歌工程师François Chollet。
Keras在代码结构上由面向对象方法编写,完全模块化并具有可扩展性,其运行机制和说明文档有将用户体验和使用难度纳入考虑,并试图简化复杂算法的实现难度 。Keras支持现代人工智能领域的主流算法,包括前馈结构和递归结构的神经网络,也可以通过封装参与构建统计学习模型。在硬件和开发环境方面,Keras支持多操作系统下的多GPU并行计算,可以根据后台设置转化为Tensorflow、Microsoft-CNTK等系统下的组件。

Keras作为神经网络的高级包,能够快速搭建神经网络,它的兼容性非常广,兼容了TensorFlow和Theano。
莫烦老师推荐大家先了解神经网络基础原理,然后学习Theano教程和TensorFlow教程,作者也非常同意老师的建议,该系列文章也是先介绍基础原理,然后介绍TensorFlow用法,最终过渡到Keras,这样大家更容易上手Python人工智能。
Keras这部分内容,我准备讲解的流程如下:
- 首先分享Keras基础原理及语法
- 接着使用Keras搭建回归神经网络、分类神经网络、CNN、RNN、LSTM、Autoencoder等
- 最后结合Keras实现各种自然语言处理、图像分类、文本挖掘、语音识别、视频分析等案例
希望大家喜欢,同时补充一句,作者也是人工智能的初学者,也不是什么大牛,只是简简单单分享自己的学习过程,并结合之前大数据分析的经验实现一些有用的案例,希望能帮助到大家,开始吧!
强推大家学习莫烦老师AI教程:
- https://morvanzhou.github.io/tutorials
二.安装Keras和兼容Backend
1.如何安装Keras
首先需要确保已经安装了以下两个包:
- Numpy
- Scipy
调用“pip3 list”命令可以看到相关包已经安装成功。
接着通过“pip3 install keras”安装,作者是使用Anaconda下的Python3.6版本。
activate tensorflow pip3 install keras pip install keras
搭建过程详见这篇文章:
安装如下图所示:
安装成功之后,我们尝试一个简单的代码。打开Anaconda,然后选择已经搭建好的“tensorflow”环境,运行Spyder。
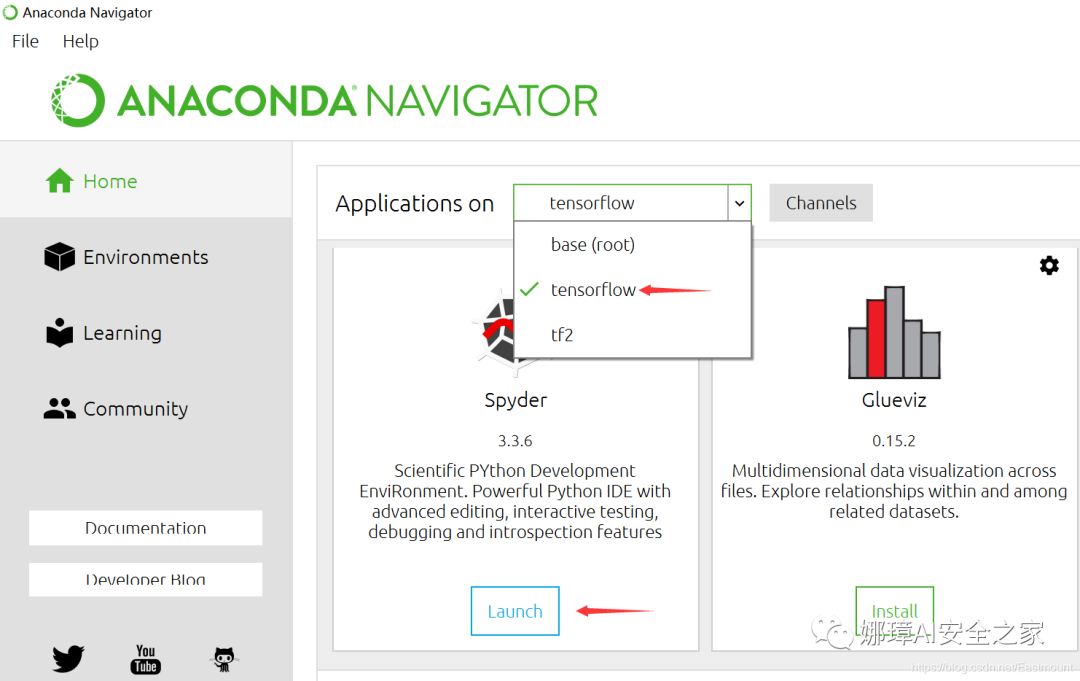
测试代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Feb 14 16:43:21 2020
@author: Eastmount CSDN
"""
import numpy as np
from keras.preprocessing.sequence import TimeseriesGenerator
# 时间序列
y = np.array(range(5))
tg = TimeseriesGenerator(y, y, length=3, sampling_rate=1)
for i in zip(*tg[0]):
print(*i)
运行结果如下图所示,究竟“Using TensorFlow backend.”表示什么意思呢?

2.兼容Backend
Backend是指Keras基于某个框架来做运算,包括基于TensorFlow或Theano,上面的那段代码就是使用TensorFlow来运算的。后面要讲解的神经网络也是基于TensorFlow或Theano来搭建的。
如何查看Backend呢?当我们导入Keras扩展包时,它就会有相应的提示,比如下图使用的就是Theano来搭建底层的神经网络。

如果想要改成TensorFlow,怎么办呢?
- 第一种方法,找到“keras/keras.json”这个文件,然后打开它。所有的backend信息就存储在这里,每次导入Keras包就会检测这个“keras.json”文件的backend。接着我们尝试修改。


- 第二种方法是在命令行中输入下面这句命令,每次运行脚本时它会直接帮你修改成临时的TensorFlow。
import os os.environ['KERAS_BACKEND']='tensorflow' import keras
三.白话神经网络
该部分还是有必要再给大家普及一遍,参考"莫烦大神"网易云课程对神经网络的介绍,讲得清晰透彻,推荐大家阅读。开始吧!让我们一起进入神经网络和TensorFlow的世界。

首先,什么是神经网络(Neural Networks)?
计算机神经网络是一种模仿生物神经网络或动物神经中枢,特别是大脑的结构和功能,它是一种数学模型或计算机模型。神经网络由大量的神经元连接并进行计算,大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应的过程。
现代神经网络是一种基于传统统计学建模的工具,常用来对输入和输出间复杂的关系进行建模,或探索数据间的模式,神经网络是一种运算模型,有大量的节点或神经元及其联系构成。和人类的神经元一样,它们负责传递信息和加工信息,神经元也能被训练或强化,形成固定的神经形态,对特殊的信息有更强烈的反应。
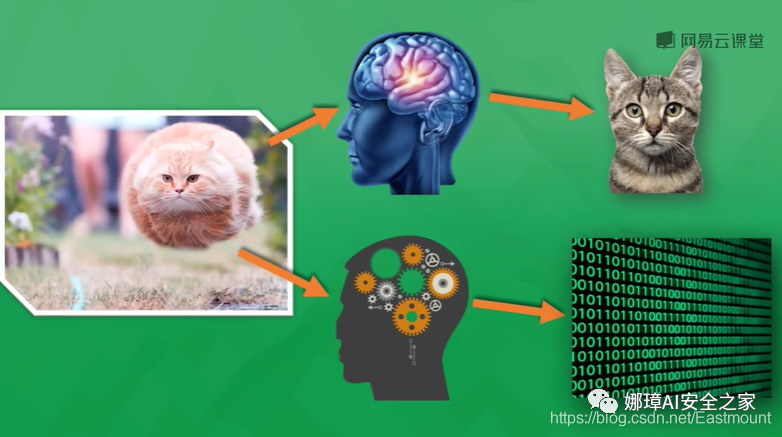
神经网络是如何工作的呢?
如上图所示,不管这是一只跳跃飞奔的猫,或是一只静静思考的猫,你都知道它是一只猫,因为你的大脑已经被告知过圆眼睛、毛茸茸、尖耳朵的就是猫,你通过成熟的视觉神经系统判断它是猫。计算机也是一样,通过不断的训练,告诉哪些是猫、哪些是狗、哪些是猪,它们会通过数学模型来概括这些学习的判断,最终以数学的形式(0或1)来分类。目前,谷歌、百度图片搜索都能清晰识别事物,这些都归功于计算机神经系统的飞速发展。
神经网络系统由多层神经层构成,为了区分不同的神经层,我们分为:
- 输入层:直接接收信息的神经层,比如接收一张猫的图片
- 输出层:信息在神经元中传递中转和分析权衡,形成输出结果,通过该层输出的结果可以看出计算机对事物的认知
- 隐藏层:在输入和输出层之间的众多神经元连接组成的各个层面,可以有多层,负责对传入信息的加工处理,经过多层加工才能衍生出对认知的理解
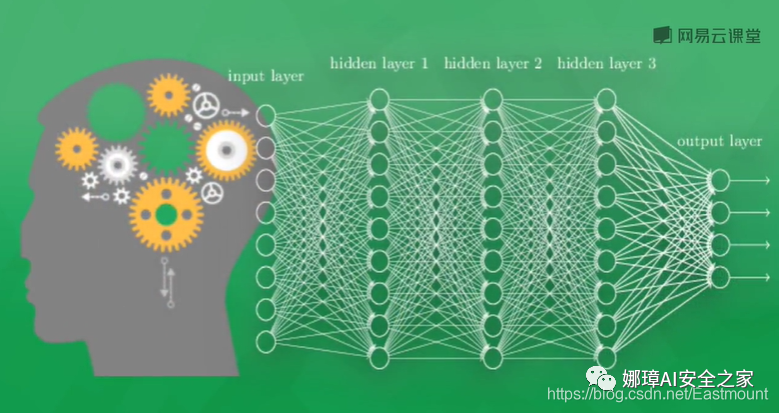
神经网络举例说明
如下图所示,通常来说,计算机处理的东西和人类有所不同,无论是声音、图片还是文字,它们都只能以数字0或1出现在计算机神经网络里。神经网络看到的图片其实都是一堆数字,对数字的加工处理最终生成另一堆数字,并且具有一定认知上的意义,通过一点点的处理能够得知计算机到底判断这张图片是猫还是狗。
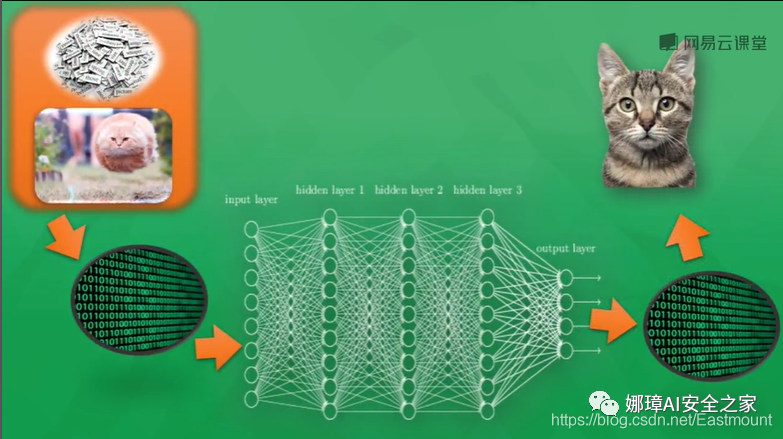
计算机是怎么训练的呢?
首先,需要很多的数据,比如需要计算机判断是猫还是狗,就需要准备上千万张有标记的图片,然后再进行上千万次的训练。计算机通过训练或强化学习判断猫,将获取的特征转换为数学的形式。

我们需要做的就是只给计算机看图片,然后让它给我们一个不成熟也不准确的答案,有可能100次答案中有10%是正确的。如果给计算机看图片是一张飞奔的猫(如下图),但计算机可能识别成一条狗,尽管它识别错误,但这个错误对计算机是非常有价值的,可以用这次错误的经验作为一名好老师,不断学习经验。
那么计算机是如何学习经验的呢?
它是通过对比预测答案和真实答案的差别,然后把这种差别再反向传递回去,修改神经元的权重,让每个神经元向正确的方向改动一点点,这样到下次识别时,通过所有改进的神经网络,计算机识别的正确率会有所提高。最终每一次的一点点,累加上千万次的训练,就会朝正确的方向上迈出一大步。
最后到验收结果的时候,给计算机再次显示猫的图片时,它就能正确预测这是一只猫。

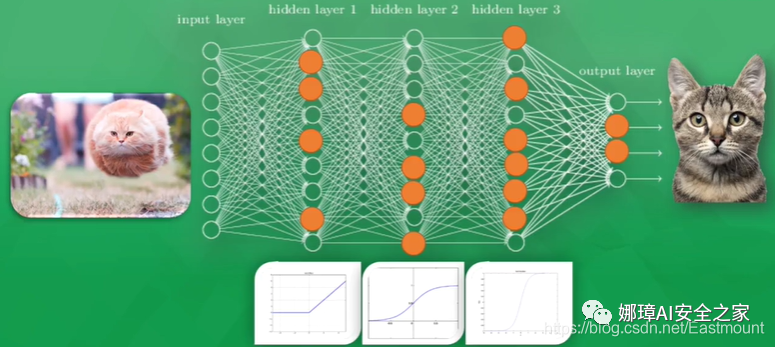
激励函数是什么东东?
接着再进一步看看神经网络是怎么训练的。原来在计算机里每一个神经元都有属于它的激励函数(Active Function),我们可以利用这些激励函数给计算机一个刺激行为。当我们第一次给计算机看一只飞奔的猫时,神经网络中只有部分神经元被激活或激励,被激活传递下去的信息是计算机最为重视的信息,也是对输出结果最有价值的信息。

如果预测的结果是一只狗,所有神经元的参数就会被调整,这时有一些容易被激活的神经元就会变得迟钝,而另一些会变得敏感起来,这就说明了所有神经元参数正在被修改,变得对图片真正重要的信息敏感,从而被改动的参数就能渐渐预测出正确的答案,它就是一只猫。这就是神经网络的加工过程。
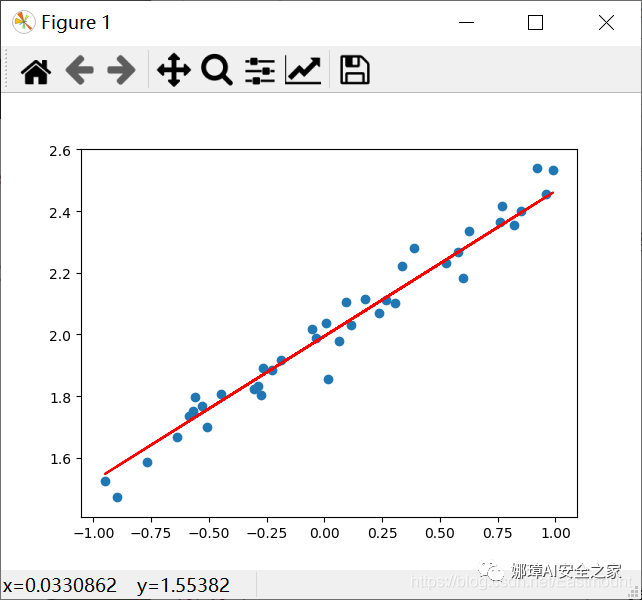
四.Keras搭建回归神经网络
推荐前文《二.TensorFlow基础及一元直线预测案例》,最终输出的结果如下图所示:
1.导入扩展包
Sequential(序贯模型)表示按顺序建立模型,它是最简单的线性、从头到尾的结构顺序,不分叉,是多个网络层的线性堆叠。Dense是layers中的属性,表示全连接层。
Keras还可以实现各种层,包括core核心层、Convolution卷积层、Pooling池化层等非常丰富有趣的网络结构。
import numpy as np from keras.models import Sequential from keras.layers import Dense import matplotlib.pyplot as plt
2.创建散点图数据
通过numpy.linspace随机生成200个散点,并构建y=0.5*x+2的虚拟数据,并调用 np.random.normal(0, 0.05, (200,)) 增加噪声。
import numpy as np from keras.models import Sequential from keras.layers import Dense import matplotlib.pyplot as plt #---------------------------创建散点数据--------------------------- # 输入 X = np.linspace(-1, 1, 200) # 随机化数据 np.random.shuffle(X) # 输出 y = 0.5*X + 2 + np.random.normal(0, 0.05, (200,)) #噪声平均值0 方差0.05 # 绘制散点图 plt.scatter(X, y) plt.show() # 数据集划分(训练集-测试集) X_train, y_train = X[:160], y[:160] # 前160个散点 X_test, y_test = X[160:], y[160:] # 后40个散点
这里通过matplotlib简单绘制散点图,输出结果如下图所示,基本满足:y = 0.5*x + 2 + noise。
3.添加神经网络层
- 创建Sequential模型。
- 添加神经网络层。在Keras中,增加层的操作非常简单,调用model.add(Dense(output_dim=1, input_dim=1))函数添加即可。注意,如果再添加一个神经层,默认上一层的输出为下一层的输入数据,此时不需要定义input_dim,比如model.add(Dense(output_dim=1, ))。
- 搭建模型并选择损失函数(loss function)和优化方法(optimizing method)。
#----------------------------添加神经层------------------------------ # 创建模型 model = Sequential() # 增加全连接层 输出个数和输入个数(均为1个) model.add(Dense(output_dim=1, input_dim=1)) # 搭建模型 选择损失函数(loss function)和优化方法(optimizing method) # mse表示二次方误差 sgd表示乱序梯度下降优化器 model.compile(loss='mse', optimizer='sgd')
PS:是不是感觉Keras代码比TensorFlow和Theano都简洁很多,但还是建议大家先学习前者,再深入Keras。
4.训练并输出误差
print("训练")
# 学习300次
for step in range(301):
# 分批训练数据 返回值为误差
cost = model.train_on_batch(X_train, y_train)
# 每隔100步输出误差
if step % 100 == 0:
print('train cost:', cost)
5.测试神经网络并输出误差\权重和偏置
print("测试")
# 运行模型测试 一次传入40个测试散点
cost = model.evaluate(X_test, y_test, batch_size=40)
# 输出误差
print("test cost:", cost)
# 获取权重和误差 layers[0]表示第一个神经层(即Dense)
W, b = model.layers[0].get_weights()
# 输出权重和偏置
print("weights:", W)
print("biases:", b)
6.绘制预测图形
y_pred = model.predict(X_test) plt.scatter(X_test, y_test) plt.plot(X_test, y_pred) plt.show()
输出结果如下所示:
误差从4.002261下降到0.0030148015,说明学习到知识。同时,误差为0.47052705接近我们的初始值0.5,偏置为1.9944116也接近2。
训练 train cost: 4.002261 train cost: 0.07719966 train cost: 0.005076804 train cost: 0.0030148015 测试 40/40 [==============================] - 0s 1ms/step test cost: 0.0028453178238123655 weights: [[0.47052705]] biases: [1.9944116]
完整代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Feb 14 16:43:21 2020
@author: Eastmount CSDN YXZ
O(∩_∩)O Wuhan Fighting!!!
"""
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
import matplotlib.pyplot as plt
#---------------------------创建散点数据---------------------------
# 输入
X = np.linspace(-1, 1, 200)
# 随机化数据
np.random.shuffle(X)
# 输出
y = 0.5*X + 2 + np.random.normal(0, 0.05, (200,)) #噪声平均值0 方差0.05
# 绘制散点图
# plt.scatter(X, y)
# plt.show()
# 数据集划分(训练集-测试集)
X_train, y_train = X[:160], y[:160] # 前160个散点
X_test, y_test = X[160:], y[160:] # 后40个散点
#----------------------------添加神经层------------------------------
# 创建模型
model = Sequential()
# 增加全连接层 输出个数和输入个数(均为1个)
model.add(Dense(output_dim=1, input_dim=1))
# 搭建模型 选择损失函数(loss function)和优化方法(optimizing method)
# mse表示二次方误差 sgd表示乱序梯度下降优化器
model.compile(loss='mse', optimizer='sgd')
#--------------------------------Traning----------------------------
print("训练")
# 学习300次
for step in range(301):
# 分批训练数据 返回值为误差
cost = model.train_on_batch(X_train, y_train)
# 每隔100步输出误差
if step % 100 == 0:
print('train cost:', cost)
#--------------------------------Test-------------------------------
print("测试")
# 运行模型测试 一次传入40个测试散点
cost = model.evaluate(X_test, y_test, batch_size=40)
# 输出误差
print("test cost:", cost)
# 获取权重和误差 layers[0]表示第一个神经层(即Dense)
W, b = model.layers[0].get_weights()
# 输出权重和偏置
print("weights:", W)
print("biases:", b)
#------------------------------绘制预测图形-----------------------------
y_pred = model.predict(X_test)
plt.scatter(X_test, y_test)
plt.plot(X_test, y_pred, "red")
plt.show()
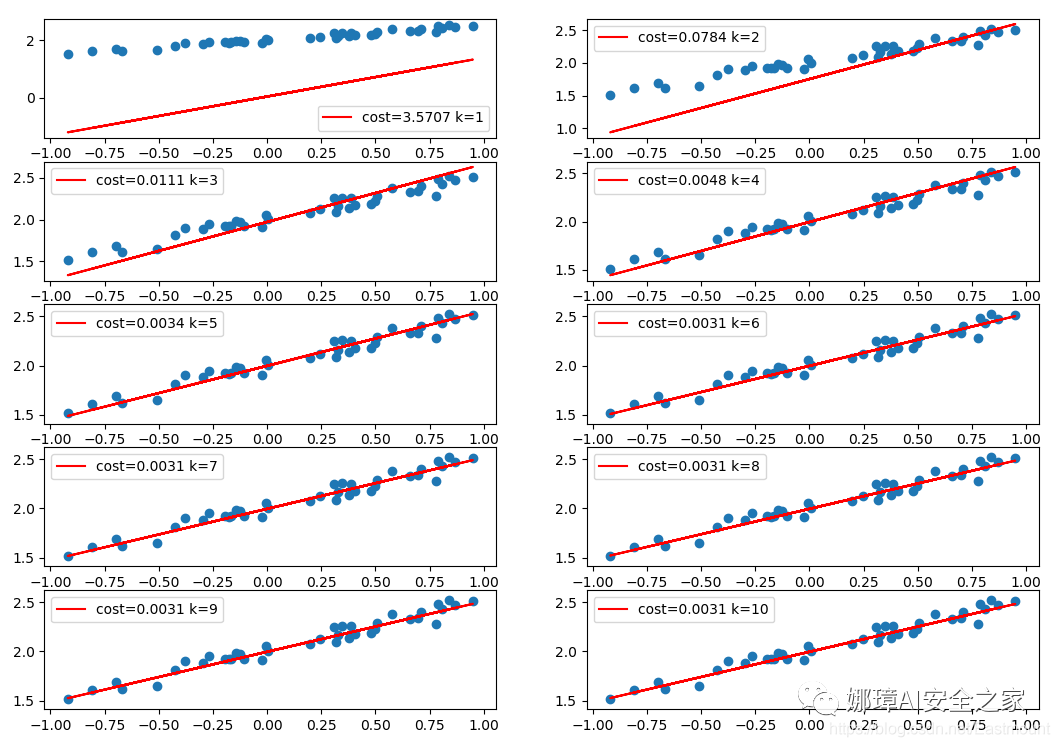
下面补充代码对比各训练阶段拟合的直线,可以看到随着训练次数增加,误差逐渐降低并且拟合的直线越来越好。
# -*- coding: utf-8 -*-
"""
Created on Fri Feb 14 16:43:21 2020
@author: Eastmount CSDN YXZ
O(∩_∩)O Wuhan Fighting!!!
"""
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
import matplotlib.pyplot as plt
#---------------------------创建散点数据---------------------------
# 输入
X = np.linspace(-1, 1, 200)
# 随机化数据
np.random.shuffle(X)
# 输出
y = 0.5*X + 2 + np.random.normal(0, 0.05, (200,)) #噪声平均值0 方差0.05
# 绘制散点图
# plt.scatter(X, y)
# plt.show()
# 数据集划分(训练集-测试集)
X_train, y_train = X[:160], y[:160] # 前160个散点
X_test, y_test = X[160:], y[160:] # 后40个散点
#----------------------------添加神经层------------------------------
# 创建模型
model = Sequential()
# 增加全连接层 输出个数和输入个数(均为1个)
model.add(Dense(output_dim=1, input_dim=1))
# 搭建模型 选择损失函数(loss function)和优化方法(optimizing method)
# mse表示二次方误差 sgd表示乱序梯度下降优化器
model.compile(loss='mse', optimizer='sgd')
#--------------------------------Traning----------------------------
print("训练")
k = 0
# 学习1000次
for step in range(1000):
# 分批训练数据 返回值为误差
cost = model.train_on_batch(X_train, y_train)
# 每隔100步输出误差
if step % 100 == 0:
print('train cost:', cost)
#-----------------------------------------------------------
# 运行模型测试 一次传入40个测试散点
cost = model.evaluate(X_test, y_test, batch_size=40)
# 输出误差
print("test cost:", cost)
# 获取权重和误差 layers[0]表示第一个神经层(即Dense)
W, b = model.layers[0].get_weights()
# 输出权重和偏置
print("weights:", W)
print("biases:", b)
#-----------------------------------------------------------
# 可视化绘图
k = k + 1
plt.subplot(5, 2, k)
y_pred = model.predict(X_test)
plt.scatter(X_test, y_test)
plt.plot(X_test, y_pred, "red", label='cost=%.4f k=%d' %(cost,k))
plt.legend()
plt.show()
六.总结
写到这里,这篇基础性的Keras文章就讲述完毕。它通过不断地训练和学习,将预测结果与实际直线y=0.5*x+2相匹配,这是非常基础的一篇深度学习文章。
最后,希望这篇基础性文章对您有所帮助,如果文章中存在错误或不足之处,还请海涵~作为人工智能的菜鸟,我希望自己能不断进步并深入,后续将它应用于图像识别、网络安全、对抗样本等领域,指导大家撰写简单的学术论文,一起加油!